Exploring AI CPU-Inferencing with Azure Cobalt 100
In this post
🔥 Azure Cobalt 200
A couple of weeks after this post went live, Microsoft unveiled the Azure Cobalt 200, a custom Arm Neoverse V3–based CPU. It will become available to customers in early 2026.
I’ve always had a soft spot for Arm devices. They consistently punch above their weight while sipping a fraction of the power used by x86_64 chips. That efficiency has fueled an entire ecosystem of clever IoT boards powering everything from hobbyist hacks to serious industrial prototypes and production systems. And now, that same efficiency is driving a much bigger shift across the industry: the use of custom silicon.
These days, performance-per-watt — basically, how much performance you can squeeze out of a single watt of power — is one of the numbers that really counts, whether you’re building something that fits in your pocket, runs at the network edge, or scales inside a massive Azure datacenter. Over the past few decades, Arm built its reputation on efficiency — beginning in embedded and early microcomputers, rising to dominance in mobile and the IoT boom — and that same strength now carries it into the mainstream, powering laptops, desktops and an ever-growing range of server-class systems.
💡 Note
I may be a little fuzzy on the exact timeline here — I tend to mentally anchor some of these things to some of Azure’s product launches… 🙃 But, roughly, that’s when I started paying closer attention.
The tradeoff when choosing Arm has been, and in some cases still is, software availability. Build artifacts, libraries and vendor tooling have historically favored x86_64. That’s not particularly surprising: once a technology becomes the dominant platform, the ecosystem naturally consolidates around it, reinforcing the cycle.
For architects and engineering leads, that translates into practical questions about CI/CD pipelines, container images, third-party binaries and long-tail compatibility. These days, though, that story is shifting significantly. Arm builds are often a first-class option across major Linux distributions and most public cloud platforms. Search for your favorite open-source project and add ARM64 (or AArch64) to it — chances are, you’ll get a hit.
That said, there are still some gaps. In my opinion, the decision to move to Arm is rarely purely technical. It can carry migration, testing, and operational costs that impact time to market and, ultimately, total cost of ownership.
But to be honest, that’s not the story I want to focus on here. There’s a much bigger picture emerging, it is one that’s unfolding at cloud scale. And not just within Microsoft Azure, mind you.
💡 Note
At its core, the Arm story isn’t just about chips; it’s about the ecosystem and how companies can leverage it. Unlike Intel or AMD, Arm doesn’t sell finished CPUs. It licenses its designs, enabling companies like Apple, Amazon, and Microsoft to build custom silicon tailored to their workloads.
I wanted to dig into why Arm devices are often described as more energy-efficient — and, more recently, why some Arm systems can even outperform comparable x86_64 chips. At the same time, it’s worth asking: does that consensus still hold today? Was there a window where x86_64 missed an opportunity? Or are we simply seeing the results of ecosystem maturity and design evolution?
What follows is my attempt to piece together the technical and practical factors that explain how we got here. Having grown up around Intel and AMD, I’ll admit Arm products always felt somewhat alien to me. That curiosity led me to look not just at performance, but also at Arm’s licensing model — which turns out to be fascinating. Once you understand the flexibility it provides, you start to see why the biggest players are investing so heavily in it.
💡 Note
Unlike Intel or AMD, Arm doesn’t sell finished CPUs; it licenses its designs, allowing major tech players to build custom silicon for everything from phones to hyperscale infrastructure. Bare with my, because there’s a bit of scene setting that I think is important to understand where this shift is coming from.
Since my work typically revolves around Microsoft Azure, I decided to take a close look at Azure Cobalt 100. I keep seeing claims that CPU-based AI inference for LLM or SLM workloads is viable—but I wanted to test what you can actually get out of the current VM offerings. More importantly: I wanted to know if it’s actually any it good?
But before we get there, we’ll also need to dive into some of the lower-level concepts that make LLMs work. Understanding these pieces in parallel is kind of important — otherwise, none of the performance data will make much sense.
⏳ TL;DR
The goal here is to provide context and data for evaluating Arm in real AI CPU-based inferencing workloads — exploring performance, efficiency, and operational implications — while giving a peek under the hood to separate practical reality from the hype.
Childhood to Cloud: Witnessing Arm’s Growth
I still remember my childhood fascination with one particular Arm technology implementation, mainly because of one device that defined an era: the Game Boy Advance. At 11 years old, I spent countless hours with a device that sold by the millions and was powered by an ARM7TDMI processor implementing the ARMv4T (T for Thumb) instruction set—a confusingly numbered scheme, but we’ll get to that in a moment. The gaming experience was quite remarkable: battery life varied from model to model, lasting anywhere between seven and 15 hours. That level of endurance was nothing short of astonishing and a perfect early example of a strong performance-per-watt ratio.
👾 Note
I distinctly remember feeling like my brain had fried after long sessions of Golden Sun, because the battery just wouldn’t give out. Looking it up now, depending on the model, your GBA could last anywhere from 7 to 15 hours on a pair of AAs. Again, I think that’s pretty incredible given what this device was capable of.
It wasn’t until I encountered the HTC Hero in 2009 that I began to pay more attention to Arm processors. They were the brains behind my smartphone — handling everyday tasks with ease and keeping me online through full days of college life. Android 2.1 “Eclair” ran smoothly on it, and while it couldn’t handle heavy workloads like an IDE, it was perfect for email, web browsing, YouTube, social media and reading books. Coming from one of those mid-2000s Samsung flip phones, the jump felt absolutely crazy.
My perspective shifted once more when devices like the Raspberry Pi Model B+ emerged, and then again when IoT on Azure gained traction around 2018. These devices weren’t just for fun anymore; they were being used in “serious” applications, acting as managed gateways to collect sensor telemetry and securely forward it to backends in Azure. In fact, I even ordered the Microsoft IoT Pack for Raspberry Pi 3 so that our team could experiment with it and understand what developers and operations had to do to integrate these devices into Azure’s ecosystem.
Then came rumors of Apple making another CPU transition — this time to Arm-based chips. Having read about Apple move from Motorola 68k to PowerPC and then subsequently watch them move to Intel — I still remember my second-gen MacBook Pro from 2007 with its Core 2 Duo — it was clear they knew how to pull off a relatively smooth transition.
They made what I’d label the most successful transition to Arm, in the personal computer space, by introducing their Apple Silicon (M-series Macs) and, notably, Rosetta 2. On these machines, you can run AArch64-compiled applications natively while x86_64 apps are smoothly translated using a combination of just-in-time (JIT) and ahead-of-time (AOT) mechanisms. This setup not only demonstrates the raw performance of Arm but also its power efficiency—so much so that even under demanding workloads like video game rendering and complex physics simulations, these M-series Macs could outperform their Intel counterparts. It was a revelation that Arm wasn’t just a low-powered alternative to x86_64, but it could even deliver top-tier performance while conserving energy. How “Insanely Great”.
Windows on Arm: Past, Present & Future
This evolution naturally leads to questions:
- Where does this leave Microsoft Windows?
- How well is Arm adoption progressing on that front?
As Arm chips continue to make headway into mainstream computing and even server markets, it’ll be interesting to see how Windows adapts and whether similar performance gains can be achieved across platforms. Let’s briefly run through another small history lesson, with my take on it for whatever it’s worth.
In my opinion, it seems like Microsoft just can’t catch a break with Windows on Arm (WoA); the transition to Arm just hasn’t worked out for Microsoft in the consumer market. It’s getting there, but it’s been a rather long bumpy process. I’m not talking about servers or the cloud just yet, purely PCs and laptops. There have been several attempts, but none have landed the way Apple Silicon did. I’d love to see Windows on Arm reach the same level of polish, because performance today is really almost there.
But Windows is a very different beast from macOS. Apple controls the entire stack (hardware, OS, runtime, developer tools, etc…) and that vertical integration is what makes Apple Silicon so seamless. macOS is optimized for a handful of known hardware configurations that Apple validates in-house; if you try to build a Hackintosh (a PC that runs macOS), you’re completely on your own.
Microsoft, on the other hand, carries decades of backward compatibility, countless subsystems and a vast hardware and software partner ecosystem that must remain intact. That is not a trivial port. To succeed, I feel Windows on Arm has to make existing apps “just work” — and do so with performance that feels on par (or better) than x86_64. Achieving that requires extremely careful engineering and design trade-offs.
💡 Note
This isn’t the first time Microsoft has faced a major architecture shift. Back in the early 2000s, the company had to move Windows to 64-bit, and there were two contenders: Intel’s Itanium (IA-64) and AMD64. IA-64 was a clean break from x86 and would have forced developers to rewrite software, while AMD64 offered backward compatibility and a much smoother path forward.
Dave Plummer, a former Microsoft operating system engineer, who shares excellent Windows history deep-dives on his YouTube channel covers this transition in detail. I totally recommend taking a look.
In 2013, a couple of my colleagues bought the first Surface RT, running Windows RT 8.1 on 32-bit Arm (ARMv7). The pitch was great battery life, but the reality was harsh: the OS only supported Universal Windows Platform apps. The situation at the time was that devs weren’t too excited to build for UWP and end-users just wanted their Win32 apps back. I personally felt like I had just learned how to use WinForms and Windows Presentation Foundation and having to learn another thing was one too many. Hardware-wise it was novel, but I suppose the ecosystem push flopped.
Then came Continuum on Windows 10 Mobile, which allowed you to connect your phone to a monitor, keyboard, and mouse to create a pseudo-desktop experience. It was a clever idea, but like earlier attempts, it suffered from limited software support and failed to gain momentum.
💡 Note
I nearly swapped my laptop for a Lumia 950 back then, but early reviews killed the idea. I stayed on my Surface, an x86_64 one.
The Surface Pro X in 2020 showed progress with an x86_64 emulation layer. Then Project Volterra arrived in 2022, pitched as an Arm developer kit. More recently, the Snapdragon X Elite Dev Kit was announced at Build 2024 — only for Qualcomm to cancel it later that year. Meanwhile, the Snapdragon X Elite laptops are still shipping, and reviewers often praise their battery life and performance for productivity workloads. As I’m writing this, a Snapdragon X2 Elite has also been announced!
So… Why does adoption keep stalling? Well.. If you ask me, I think it’s probably because unlike Apple, Microsoft can’t just flip the vertical-integration switch. Where Apple seems to go scorched earth on parts of its tech stack, Microsoft plays a different game. Windows depends on a vast ecosystem of third-party hardware and software, which makes legacy x86_64 support non-negotiable. Especially in the enterprise world, no one wants to risk breaking their long tail of Win32 apps.
To Microsoft’s credit, though, the story is improving. At the Surface Pro 11E launch in May 2024, the company said that “90% of total app minutes today are spent in native Arm apps.” That’s a huge step forward. They also introduced the new Prism emulator, included with Windows 11 24H2, which promises noticeably better performance for the x86_64 apps that still need to run under emulation.
💡 Note
I always feel like WoA is just one more Build or Ignite away from being Apple levels of good. Unfortunately there’s just not a lot of noise coming out of Microsoft on this particular topic right now. Let’s hope that changes soon!
It’s progress, but still a reminder that Microsoft’s challenge is fundamentally different. Apple won because of vertical integration. I personally think Microsoft’s task is to herd an ecosystem without breaking too much legacy compatibility.
Arm’s ecosystem in a nutshell
Before we can talk about Microsoft’s Cobalt 100, it’s worth pausing to ask: who and what exactly is Arm?
Arm Holdings, based in Cambridge, UK, is not a chip manufacturer like Intel or AMD. Instead, Arm’s business is built on designing and licensing CPU technology. They create the instruction set architecture (ISA), the fundamental “language” a processor speaks, along with reference core designs (Cortex, Neoverse, etc.). Partners then license this intellectual property and either use Arm’s own cores or design their own custom silicon that implements the Arm ISA.
💡 Note
These partners range from Apple, MediaTek, Google, Meta, Nvidia, Microsoft, etc…
This licensing-first model has made Arm the most widely deployed processor architecture in history. More than 325 billion Arm-based chips have shipped, powering everything from my very own Game Boy Advance to smartphones, servers, and supercomputers.
How Arm’s licensing works
It’s not too complex actually, you can think of it in two main flavors:
- Core licences: Companies license ready-made Arm-designed cores designs (like Cortex-A or Cortex-M) and integrate them into their own System on Chips (SoCs), alongside GPUs, radios, or custom accelerators. This is the fast path; you get proven IP with low risk.
- Architectural licences: The more expensive option. Big players (Apple, Amazon, Qualcomm) license the Arm ISA itself, then design their own custom cores from scratch, as long as they faithfully implement the ISA. This enables differentiation; Apple’s M-series CPUs, for example, are Arm ISA–compatible but not Cortex designs.
This model means Arm CPUs are everywhere, but not all Arm CPUs are the same.
Arm ISA: the software contract
At the foundation is the Arm Instruction Set Architecture (ISA). It’s the contract between hardware and software: defining what instructions exist, how memory ordering works, and what guarantees an operating system can rely on. Conceptually, I feel it’s a bit like an interface in .NET (a formal agreement about how two sides interact) but in this case, the two sides are software and hardware. It lets you write code for the system without knowing the implementation details of the hardware.
- Naming scheme:
Armv<revision>-<profile>(e.g.Armv9-A,Armv8-M). - Profiles:
- A-Profile: application processors (laptops, smartphones, servers).
- R-Profile: real-time processors (brakes, controllers).
- M-Profile: microcontrollers (IoT, wearables).
- Since Armv8, there are two execution states: AArch64 (64-bit) and AArch32 (legacy 32-bit). Modern Arm systems (like Snapdragon X Elite, Cobalt 100) run in 64-bit mode.
Different microarchitectures (e.g., Cortex-X, Neoverse V-series, Apple M-series) implement the same ISA but can vary wildly in pipeline depth, cache design, or power efficiency. That separation is why Arm can scale from a USD 1 IoT chip to a USD 10,000 server CPU — the ISA guarantees software compatibility across them all.
Arm CPU families
Arm organizes its IP into several, albeit a little convoluted, families:
- Cortex-A: application-class cores (smartphones, tablets, PCs).
- Cortex-X: a performance-focused branch of Cortex-A.
- Cortex-R: real-time cores (automotive, storage).
- Cortex-M: microcontroller-class cores (IoT, embedded).
- Neoverse: infrastructure cores designed for datacenters and networking.
On the GPU side, Arm also licenses Mali and the newer Immortalis (ray-tracing capable). For AI, there’s the Ethos NPU line.
Arm’s 2025 Rebranding
In May 2025, Arm announced a rebrand of its product naming architecture. Each Compute Subsystem (CSS) platform will now carry a clear identity aligned to its target market:
- Arm Neoverse: Infrastructure
- Arm Niva: PC
- Arm Lumex: Mobile
- Arm Zena: Automotive
- Arm Orbis: IoT
The Mali name will continue as Arm’s GPU brand, with IP referenced as components within these platforms. Arm has also simplified its CPU core naming: cores are now aligned with platform generations and use descriptive tiers like Ultra, Premium, Pro, Nano, and Pico to indicate performance levels. For example in the Lumex CSS platform we have the following products:
I could not find any information regarding a possible C1-Pico, so for now I will simply assume it does not yet exist.
Into the Neoverse
The Arm Neoverse family is a set of 64-bit Arm CPU cores designed for datacenters, edge deployments and high-performance computing. It consists of three product lines:
- Neoverse V-Series: Maximum Performance
- Performance-first CPUs optimized for demanding compute- and memory-intensive applications.
- Use Cases: HPC, cloud-based HPC, and AI/ML workloads.
- Neoverse N-Series: Scale-Out Performance
- Balanced CPU design that emphasizes both performance per watt and performance per dollar.
- Use Cases: scale-out cloud, enterprise networking, smartNICs/DPUs and custom ASIC accelerators, 5G infrastructure and power and space-constrained edge locations.
- Neoverse E-Series: Efficient Throughput
- Energy-efficient CPUs designed for high data throughput with minimal power consumption.
- Use Cases: Networking data plane processor, 5G deployments for low power gateways.
And it’s those Neoverse N-Series processors that are intended for core datacenter usage:
- Neoverse N1
- Based on Cortex-A76, runs on ARMv8.2-A instruction set.
- Example: Ampere Altra
- Neoverse N2
- Based on Cortex-A710, running the ARMv9.0-A ISA.
- Example: Azure Cobalt 100
Arm announced the Neoverse N2 in 2020 as a licensable CPU core design. Like other Arm IP, customers could integrate it into custom SoCs. As you might already expect, Microsoft’s Cobalt 100 is example of this design approach.
💡 Note
A Neoverse V2 implementation can be found in AWS Graviton4 and Google Axion. When I began writing this post there were mentions of an Azure Cobalt 200 floating around online, but Microsoft had yet to announce any details. As of Ignite 2025, Azure Cobalt 200, a Neoverse V3-based CPU, was announced. Depending on the workload, it can deliver up to 50% performance improvement over Cobalt 100 and integrates with Arm’s Confidential Compute Architecture (CCA).
Designing a server-class SoC around a CPU core like N2 is a complicated endeavour. Beyond the CPU, vendors must design and validate memory controllers, interconnects, PCIe/CXL I/O, power management and firmware. This requires large engineering teams and significant time, creating barriers for companies without deep silicon design resources.
To address this, Arm introduced Neoverse Compute Subsystems (CSS) in 2023, starting with CSS N2. Instead of just CPU cores, CSS delivers an entire pre-integrated, pre-validated subsystem — including Neoverse cores, memory and I/O controllers, interconnect fabric, system management processors and reference firmware. Arm claims this cuts months (or even a year) from design schedules, saves tens of engineering-years, and reduces risk by starting from a silicon-proven baseline. They’re probably right, I probably couldn’t build any of this in a year, let alone more.
💡 Note
Neoverse CSS is not a new licensing model! It’s an enhanced version of Arm’s traditional core license: rather than licensing only the CPU design, partners license a full subsystem. They still retain flexibility to add their own accelerators, I/O, or packaging, while accelerating time-to-market.
Arm is expanding CSS with new third-generation Neoverse IP, from what I’ve read online; Neoverse CSS N3 is able to deliver ~20% higher performance-per-watt compared to CSS N2. There is also a Neoverse CSS V3, built on new V3 IP, offers up to 50% higher performance per socket than prior CSS products.
Why this matters for Microsoft
There are clear signals that Microsoft is stepping deeper into the Arm ecosystem — both on the client side and in the cloud.
A key point is that Microsoft isn’t only just porting Windows to another CPU. It’s embracing the broader Arm model: a single instruction set architecture (ISA) that spans ultralight laptops to hyperscale servers, with core designs tuned for power, performance, or cost. That approach, especially in Azure, gives Microsoft tighter control over hardware behavior via custom silicon and brings Azure closer to the kind of vertical integration Apple has long championed.
That shift is not only about offering Arm-based virtual machines, by the way. With the AI boom accelerating, hyperscalers like Microsoft are redesigning their stacks from silicon to software to meet performance, efficiency, and total cost of ownership (TCO) demands. That combination makes Arm both appealing and challenging — and it’s why Microsoft’s shift feels more strategic and higher-stakes than simply following Intel and AMD’s x86_64 roadmap.
Arm in Microsoft Azure
Zooming in to Azure specifically, Arm-based VMs are already here and steadily improving. I’m personally still a bit cautious about recommending them, not because they aren’t promising (they are), but because most companies I work with value reliability over novelty. As long as their workloads run smoothly on x86_64, there’s little incentive to switch.
That said, Arm in Azure is maturing fast. Since the Ampere Altra–powered Dpsv5 series launched in 2022, Microsoft has been expanding its Arm footprint. These VMs dedicate a full physical core per vCPU, offering strong price–performance and energy efficiency for many workloads.
Support on the software side is catching up, too. On Linux, the ecosystem is “mostly ready” thanks to years of IoT-driven investment, though occasional driver or integration issues persist. From what I am able to find online, Windows Server on Arm is still early, limited to a few Windows Server 2025 Insider Preview builds, but the Windows 11 on Arm preview in the Azure Marketplace shows where things are headed.
Like I mentioned at the beginning, this all ties back to performance-per-watt, where Arm shines. The real question now is how long it’ll take for adoption, and confidence, to catch up.
📖 Docs
Azure VM size naming conventions use a “p” to designate Arm-based CPUs. What the “p” actually stands for remains a mystery.
All of this groundwork — the gradual rollout of Arm-based VMs, the growing ecosystem maturity and Microsoft’s push toward performance-per-watt optimization — sets the stage for a deeper transformation happening inside Microsoft’s data centers. It’s something I mentioned in the previous section. That transformation comes down to one thing: custom silicon.
Maia and Cobalt
Azure is more than just racks of servers, network cables, and power supplies. Increasingly, Microsoft is designing not just its own CPUs but also its own custom silicon, which is a clear step toward deeper vertical integration. It’s an interesting contrast to what I mentioned earlier: Apple’s success came because of vertical integration, while Microsoft’s challenge has always been to move in that direction without breaking compatibility across its massive ecosystem.
At Microsoft Ignite 2023, they unveiled two custom-designed pieces of silicon, with each serving a distinct role in their strategy:
- Maia 100 AI Accelerator: Purpose-built for artificial intelligence workloads, including generative AI.
- Powers much of Copilot’s capabilities and supports Azure OpenAI Service for large-scale inference.
- Though it is not directly available for customer provisioning.
- Cobalt 100 VM SKU: An ARM-based processor designed for general-purpose compute workloads in the Microsoft Cloud.
- First-party use case: media processing for Microsoft Teams and AI meeting features in Copilot
- Unlike Maia, Cobalt 100 is available to Azure customers as a VM SKU.
Then in 2024, Satya Nadella announced the general availability of Azure Cobalt 100. I thought it was pretty clear that it wasn’t some lab experiment, as was already powering parts of Microsoft Teams and Azure SQL Database, two of Microsoft’s most widely used services. This move signaled that, as far as Microsoft is concerned, Arm-based infrastructure was ready for prime time and gives it a really cool use-case of handling real-world workloads at scale.
📖 Docs
“These VMs utilize Microsoft’s first 64-bit Arm-based CPU, fully designed in-house. The Cobalt 100 processor, based on Arm Neoverse N2, enhances performance and power efficiency for a broad range of workloads.”
Together, Maia and Cobalt represent the another puzzle piece in Microsoft’s vertically integrated infrastructure vision. From silicon to software, servers to racks, and cooling systems to AI models, the company can now design and optimize across the entire stack with both internal and customer workloads in mind.
If you zoom out, Microsoft’s strategy looks increasingly similar to Apple’s: controlling more of the “walled garden” to deliver performance, efficiency, and tight integration. Make no mistake however, Azure still gives you a lot of freedom to do whatever it is you’d like to do.
📖 Quote
“Software is our core strength, but frankly, we are a systems company. At Microsoft we are co-designing and optimizing hardware and software together so that one plus one is greater than two. We have visibility into the entire stack, and silicon is just one of the ingredients.”
As Mark Russinovich highlighted in a Microsoft Mechanics video (early 2025), the goal behind these chips is clear: maximize performance per watt. As I’m editing this post, it’s worth noting that both Kevin Scott and Scott Guthrie have echoed this sentiment, emphasizing that custom silicon is key to achieving the best performance-per-watt for every dollar spent on energy.
🎥 YouTube
For more details, Microsoft has even put together a YouTube playlist dedicated to Cobalt 100. While a few videos lean on marketing, several go deeper into the technical design and deployment.
As of late january 2026, Microsoft announced the Maia 200 AI Accelerator an inference-focused SoC built on TSMC’s 3nm process that features native FP8/FP4 tensor cores and a redesigned memory system with 216GB of HBM3e. All of this sits within a 750W SoC TDP envelope. A software development kit will include a Triton Compiler, PyTorch support, low-level programming via NPL, and a Maia simulator with a cost calculator to optimize efficiency earlier in the code lifecycle.
Overview Azure Arm-based VM SKUs
To understand how many Arm-based VM SKUs Azure actually offers, there are a few ways to gather the list. The simplest is to browse the Azure Portal using the VM creation workflow. Alternatively, Microsoft Learn documentation maintains SKU lists, but you’ll need to scan for every “p”-series (which designates Arm). For a more programmatic approach, I used the Microsoft Azure Pricing API.
By running the following GET request with some odata filters, you can retrieve all available SKUs:
https://prices.azure.com/api/retail/prices?$filter=serviceName eq 'Virtual Machines'
and armRegionName eq 'eastus'
and startswith(armSkuName, 'Standard_')
and substring(armSkuName, 11, 1) eq 'p'
&$orderby=armSkuName
This returned ~253 results for me, though the count included Spot VMs and DevTest Labs pricing. Filtering those out gives a clearer view. Pay attention to the count property in the response, but don’t overlook the NextPageLink property, you must follow it to retrieve the full dataset.
That process gave me the following summary table of Arm-based VM series:
| VM Series | Processor | Family | Premium Disk | Local Temp Disk | Low Memory | Version | Trusted Launch |
|---|---|---|---|---|---|---|---|
| Bpsv2 | Ampere® Altra® at 3.0 GHz | Burstable | Yes | No | No | v2 | No |
| Dpdsv5 | Ampere® Altra® at 3.0 GHz | General Purpose | Yes | No | No | v5 | No |
| Dpdsv6 | Azure Cobalt 100 at 3.4 GHz | General Purpose | Yes | No | No | v6 | Yes |
| Dpldsv5 | Ampere® Altra® at 3.0 GHz | General Purpose | Yes | Yes | Yes | v5 | No |
| Dpldsv6 | Azure Cobalt 100 at 3.4 GHz | General Purpose | Yes | Yes | Yes | v6 | Yes |
| Dplsv5 | Ampere® Altra® at 3.0 GHz | General Purpose | Yes | No | Yes | v5 | No |
| Dplsv6 | Azure Cobalt 100 at 3.4 GHz | General Purpose | Yes | No | Yes | v6 | Yes |
| Dpsv5 | Ampere® Altra® at 3.0 GHz | General Purpose | Yes | No | No | v5 | No |
| Dpsv6 | Azure Cobalt 100 at 3.4 GHz | General Purpose | Yes | No | No | v6 | Yes |
| Epdsv5 | Ampere® Altra® at 3.0 GHz | Memory Optimized | Yes | Yes | No | v5 | No |
| Epdsv6 | Azure Cobalt 100 at 3.4 GHz | Memory Optimized | Yes | Yes | No | v6 | Yes |
| Epsv5 | Ampere® Altra® at 3.0 GHz | Memory Optimized | Yes | No | No | v5 | No |
| Epsv6 | Azure Cobalt 100 at 3.4 GHz | Memory Optimized | Yes | No | No | v6 | Yes |
One important note: Trusted Launch is the default for new Azure Gen2 VMs and scale sets. If you’re future-proofing workloads, I’d recommend avoiding SKUs that lack Trusted Launch.
📖 Docs
Azure Trusted Launch provides additional protection for Generation 2 VMs against advanced and persistent attack techniques. It layers multiple security features (e.g., secure boot, vTPM) that can be enabled independently.
Cost Comparison
Choosing the right SKU ultimately boils down to how your workload is classified. I’ll be running a few Small Language Model (SLM) benchmarks shortly, but from what I’ve seen online, most people start with configurations around 32 cores and 128 GiB of RAM as a baseline.
Out of curiosity, I wanted to understand how Arm64 and x86_64 SKUs compare in terms of pricing. To do that, I’ll briefly look at compute-only costs (excluding OS disks) for 32 vCPU / 128 GiB RAM setups across three popular regions.
| Region | CPU | SKU | Compute cost | Saving Plan 1y | Saving Plan 3y | Reservation 1y | Reservation 3y |
|---|---|---|---|---|---|---|---|
| East US | Ampere Altra | D32ps_v5 | 899,36 USD | 31% | 53% | 41% | 62% |
| East US | Azure Cobalt 100 | D32ps_v6 | 819,79 USD | 32% | 54% | 41% | 62% |
| East US | AMD EPYC 9004 | D32as_v6 | 1.060,69 USD | 32% | 54% | 41% | 62% |
| East US | Xeon Platinum 8573C | D32s_v6 | 1.177,49 USD | 32% | 54% | 38% | 61% |
| West US | Ampere Altra | D32ps_v5 | 1.046,82 USD | 29% | 53% | 41% | 62% |
| West US | Azure Cobalt 100 | D32ps_v6 | 957,76 USD | 32% | 54% | 41% | 62% |
| West US | AMD EPYC 9004 | D32as_v6 | 1.245,38 USD | 29% | 53% | 41% | 62% |
| West US | Xeon Platinum 8573C | D32s_v6 | 1.373,86 USD | 31% | 54% | 38% | 61% |
And in Europe:
| Region | CPU | SKU | Compute cost | Saving Plan 1y | Saving Plan 3y | Reservation 1y | Reservation 3y |
|---|---|---|---|---|---|---|---|
| West Europe | Ampere Altra | D32ps_v5 | 1.074,56 USD | 29% | 53% | 41% | 62% |
| West Europe | Azure Cobalt 100 | D32ps_v6 | 978,93 USD | 32% | 53% | 41% | 62% |
| West Europe | AMD EPYC 9004 | D32as_v6 | 1.282,61 USD | 29% | 53% | 41% | 62% |
| West Europe | Xeon Platinum 8573C | D32s_v6 | 1.410,36 USD | 31% | 54% | 38% | 61% |
The takeaway is pretty clear: Microsoft is positioning Arm SKUs aggressively. Azure Cobalt 100 is often 20%+ cheaper than comparable x86_64 instances, while also offering slight additional savings plan or reservation discounts. For memory-optimized SKUs (256 GB RAM), the difference is even starker — in East US, Cobalt E32ps_v6 is nearly $470 cheaper than Intel’s Emerald Rapids-based E32s_v6.
But the bigger question is: should you adopt these Arm-based instances instead of VMs with Nvidia GPUs, or even a managed service like Azure AI Foundry?
AI workloads on Arm
So is it really a good idea to run AI inference workloads on CPUs? Arm certainly thinks so. At Computex 2024, the company projected that more than 100 billion Arm devices will be AI-ready by the end of 2025. To get there, Arm’s strategy combines advances in both software and hardware.
On the software side, Arm introduced KleidiAI — Greek for “key”. KleidiAI is an open-source library of highly optimized, performance-critical routines (micro-kernels) that accelerate AI inference on Arm-based CPUs by leveraging modern Arm architectural features. The goal is simple: integrate KleidiAI directly into popular frameworks so developers can tap into Arm CPU performance with no extra effort. This unlocks the full capability of Arm Cortex-A, Cortex-X, and Neoverse CPUs, enabling AI where the hardware already exists.
💡 Note
Since its launch, Arm has delivered on that promise. KleidiAI is already integrated into:
On the hardware side, Arm is rolling out Compute Subsystems (CSS) for Client. CSS combines Armv9 architecture benefits with validated, production-ready implementations of the latest Arm CPUs and GPUs, built on cutting-edge 3nm process nodes. The goal is to accelerate time-to-market for silicon partners while delivering AI-ready compute blocks out of the box.
Inferencing on a CPU
Running AI inference on a CPU is not only possible — it’s becoming increasingly practical — but only if you account for some key considerations:
- Choose a CPU with hardware support for vector multiply instructions in the Arm ISA.
- Use an inference engine that takes advantage of those vectorization features.
- Feed the engine with quantized models optimized for your CPU’s capabilities.
Let’s unpack those.
ISA Support and Vectorization
Inference software like llama.cpp has been extended to work on Arm64 CPUs with NEON instructions, Arm’s SIMD (single-instruction, multiple-data) architecture. NEON accelerates workloads that require parallel arithmetic, like matrix multiplications in neural networks. The backend logic originally developed for x86_64 CPUs has been ported to Arm, with support for datatypes such as:
- FP32 (full 32-bit precision, mostly used for training, less so for inference)
- FP16 (half precision floating point, more compact and efficient)
- BF16 (Bfloat16, optimized for deep learning workloads)
Beyond NEON, Arm CPUs can also support SVE/SVE2 (Scalable Vector Extensions), which expand SIMD vector widths and allow more parallelism — that’s critical for larger models and higher throughput workloads.
To further accelerate INT8 operations, Arm added the I8MM (Integer 8-bit Matrix Multiply) extension. A representative instruction is SMMLA, which performs signed 8-bit matrix multiplies and accumulates the results into 32-bit outputs—essentially an eight-way dot product per element.
These sort of instructions are absolutely foundational for efficient integer-based AI inference.
Arm has an interesting blog post detailing how they optimized llama.cpp using the Arm I8MM instruction, it’s well worth a read.
Precision and Data Types
Most AI models are trained in FP32 (full precision) but distributed in reduced precision formats to make inference more efficient. Common datatypes include:
- BF16 (Bfloat16): Same exponent size as FP32, smaller mantissa. Retains wide dynamic range while reducing compute and memory cost.
- FP16 (Half Precision): More compact floating-point format; widely supported on GPUs and CPUs.
- INT8 (8-bit Integer): Used in quantized models; very efficient but requires careful optimization to avoid accuracy loss.
Modern GPUs, such as the NVIDIA A100 and H100, include “Tensor Cores” that can accelerate computations using BF16, FP16 and other precisions. These are specialized processing units, different from CUDA Cores, designed specifically to speed up matrix operations—such as multiplication and accumulation—far beyond the performance of standard GPU cores. On CPUs, support for these lower-precision operations depends on the underlying microarchitecture.
- Armv8.2-A ISA added BF16 as optional.
- Armv8.6-A made BF16 mandatory.
- Neoverse N2 and Neoverse V1 implement BF16 fully.
- Neoverse N1 however, often lacks native BF16, falling back to slower software emulation (though it supports FP16 in hardware).
So, while FP16 inference performs well on N1-based CPUs like Ampere Altra, BF16 acceleration becomes available only in newer designs.
Quantization: The CPU Equalizer
Because CPUs lack dedicated Tensor Cores, quantization bridges the performance gap. By reducing numerical precision, for instance, from FP32 to INT8 or INT4—quantization you can:
- Shrink model size and memory footprint.
- Cut computational cost.
- Speed up inference, often with minimal accuracy loss.
Lower-bit schemes (like 4- or 6-bit) may still rely on INT8 matrix multiply paths, meaning I8MM and SMMLA continue to deliver performance benefits even for sub-8-bit quantized models.
That’s why Arm’s I8MM-enabled CPUs (such as Neoverse N2 and Azure Cobalt 100) represent a leap forward; they accelerate not just pure INT8 inference but any quantization approach that maps onto INT8 arithmetic.
Research and Optimizations
Microsoft researchers demonstrated that heavily quantized versions of large models, such as LLaMA, can achieve near-FP16 accuracy at a fraction of the compute cost. With the right ISA extensions (NEON, I8MM, BF16/FP16) and optimized software stacks (KleidiAI, ONNX Runtime, llama.cpp), CPUs can now deliver:
- Competitive inference throughput
- Lower energy consumption than GPUs
- Cost-effective scalability across edge and data-center deployments
Let’s see if that is truly the case with some benchmarks.
Demo: Phi-4 and Llama.cpp on Cobalt 100
To demonstrate the capability of Arm-based CPUs for LLM inference, Arm and partners have optimized the INT4 and INT8 kernels in llama.cpp to leverage newer instructions such as NEON and I8MM.
For this demo, I’m rolling out a Linux VM using Standard_D64ps_v6, since this is a common starting point for Arm-based inference experiments. I’ll be running Ubuntu as the OS. The deployment uses a typical VM Bicep template, with minor modifications to the $.properties.hardwareProfile.vmSize and $.properties.storageProfile.imageReference fields.
targetScope = 'resourceGroup'
@description('Required. Specifies the Azure location where the key vault should be created.')
param location string = resourceGroup().location
@description('Required. Admin username of the Virtual Machine.')
param adminUsername string
@description('Required. Password or ssh key for the Virtual Machine.')
@secure()
param adminPasswordOrKey string
@description('Optional. Type of authentication to use on the Virtual Machine.')
@allowed([
'password'
'sshPublicKey'
])
param authenticationType string = 'password'
@description('Required. Name of the Virtual Machine.')
param vmName string
@description('Optional. Size of the VM.')
@allowed([
'Standard_D64ps_v6'
])
param vmSize string = 'Standard_D64ps_v6'
@description('Optional. OS disk type of the Virtual Machine.')
@allowed([
'Premium_LRS'
'Standard_LRS'
'StandardSSD_LRS'
])
param osDiskType string = 'Premium_LRS'
@description('Optional. Enable boot diagnostics setting of the Virtual Machine.')
@allowed([
true
false
])
param bootDiagnostics bool = false
@description('Optional. Specifies the size of an empty data disk in gigabytes. This element can be used to overwrite the size of the disk in a virtual machine image. The property \'diskSizeGB\' is the number of bytes x 1024^3 for the disk and the value cannot be larger than 1023.')
param diskSizeGB int = 128
var virtualNetworkName = '${vmName}-vnet'
var subnetName = '${vmName}-vnet-sn'
var subnetResourceId = resourceId('Microsoft.Network/virtualNetworks/subnets', virtualNetworkName, subnetName)
var addressPrefix = '10.0.0.0/16'
var subnetPrefix = '10.0.0.0/24'
resource publicIPAddress 'Microsoft.Network/publicIPAddresses@2023-06-01' = {
name: '${vmName}-ip'
location: location
sku: {
name: 'Basic'
}
properties: {
publicIPAllocationMethod: 'Dynamic'
}
}
resource networkSecurityGroup 'Microsoft.Network/networkSecurityGroups@2023-06-01' = {
name: '${vmName}-nsg'
location: location
properties: {
securityRules: [
{
name: 'SSH'
properties: {
priority: 100
protocol: 'Tcp'
access: 'Allow'
direction: 'Inbound'
sourceAddressPrefix: '*'
sourcePortRange: '*'
destinationAddressPrefix: '*'
destinationPortRange: '22'
}
}
]
}
}
resource virtualNetwork 'Microsoft.Network/virtualNetworks@2023-06-01' = {
name: virtualNetworkName
location: location
properties: {
addressSpace: {
addressPrefixes: [
addressPrefix
]
}
subnets: [
{
name: subnetName
properties: {
addressPrefix: subnetPrefix
networkSecurityGroup: {
id: networkSecurityGroup.id
}
}
}
]
}
}
resource networkInterface 'Microsoft.Network/networkInterfaces@2023-06-01' = {
name: '${vmName}-nic'
location: location
properties: {
ipConfigurations: [
{
name: 'ipconfig1'
properties: {
privateIPAllocationMethod: 'Dynamic'
subnet: {
id: subnetResourceId
}
publicIPAddress: {
id: publicIPAddress.id
}
}
}
]
}
dependsOn: [
virtualNetwork
]
}
resource confidentialVm 'Microsoft.Compute/virtualMachines@2023-09-01' = {
name: vmName
location: location
properties: {
diagnosticsProfile: {
bootDiagnostics: {
enabled: bootDiagnostics
}
}
hardwareProfile: {
vmSize: vmSize
}
storageProfile: {
osDisk: {
createOption: 'FromImage'
managedDisk: {
storageAccountType: osDiskType
}
diskSizeGB: diskSizeGB
}
imageReference: {
publisher: 'canonical'
offer: 'ubuntu-24_04-lts'
sku: 'server-arm64'
version: 'latest'
}
}
networkProfile: {
networkInterfaces: [
{
id: networkInterface.id
}
]
}
osProfile: {
computerName: vmName
adminUsername: adminUsername
adminPassword: adminPasswordOrKey
linuxConfiguration: ((authenticationType == 'password') ? null : {
disablePasswordAuthentication: true
ssh: {
publicKeys: [
{
keyData: adminPasswordOrKey
path: '/home/${adminUsername}/.ssh/authorized_keys'
}
]
}
})
}
securityProfile: {
securityType: 'TrustedLaunch'
uefiSettings: {
secureBootEnabled: true
vTpmEnabled: true
}
}
}
}
Building Llama.cpp on ARM64
SSH into the VM and update package indexes. While you could download pre-built binaries from llama.cpp GitHub releases, there is currently no official Linux ARM64 binary. Building from source requires a standard C++ toolchain:
sudo apt update
sudo apt install -y build-essential \
libcurl4-openssl-dev \
make \
cmake \
gcc \
g++
Next, we clone the llama.cpp Git repo onto our machine.
git clone https://github.com/ggerganov/llama.cpp
Create a build directory, configure CMake with CPU-specific flags, and build the project:
cd llama.cpp
mkdir build
cd build
cmake .. -DCMAKE_CXX_FLAGS="-mcpu=native" -DCMAKE_C_FLAGS="-mcpu=native"
cmake --build . -v --config Release -j `nproc`
After building, the binaries will be located in ./bin:
ls -la ./bin
cd ./bin
Installing HuggingFace CLI
We will need Python 3 to run the HuggingFace CLI. Install it and set up a virtual environment:
sudo apt install -y python-is-python3 \
python3-pip \
python3-venv
The CLI allows you to easily access models like Microsoft Phi-4 and the full Phi-4 collection, which includes mini models for constrained environments, multimodal variants, and models with reasoning or summarization capabilities.
python -m venv .env
source .env/bin/activate
Next we install huggingface_hub from the PyPi registry:
pip install --upgrade huggingface_hub
Microsoft Phi-4 as a Benchmark Model
For the benchmark, I decided to use Microsoft’s Phi-4 model as a starting point. This is the base model variant, but the full Phi-4 collection contains a wide range of alternatives:
- Mini models: tuned for resource-constrained environments, with or without reasoning and summarization.
- Multimodal models: capable of handling not just text, but also audio and images.
The base Phi-4 model comes with a few important characteristics:
- Small language model, not large.
- Parameters: 14.7B
- Tensor type: BF16 (16-bit precision)
- Context window: 16,000 tokens
- Model layers: 40
- File format: Safetensors (GPU-ready)
- Architecture: dense decoder-only transformer
Parameter Memory
With 16-bit precision, each parameter requires 2 bytes of storage. That means just the parameters themselves take up:
14.7B x 2 bytes = 29.4 GB
Context Window
The context window determines how many tokens the model can handle in a single forward pass. For Phi-4:
16,000 tokens x 2 bytes ≈ 32 KB
This is relatively small compared to parameter memory, but it’s only part of the full story.
Activation Memory
While the parameter size gives us a starting point for estimating memory requirements, it doesn’t capture everything that ends up happening during inference. When an LLM processes an input and produces an output, it runs through an enormous sequence of calculations across all its layers. Along the way, the model generates activations, those are the intermediate results of said calculations. It’s kind of similar to docker build’s intermediate layers, if you ask me, they exist temporarily to pass information along
It’s important to understand the difference:
- Hidden layers are the computational layers themselves: the set of operations (attention, feed-forward, etc.) that transform one representation into another.
- Activations are the actual outputs of these hidden layers for a given input: the vectors that hold the intermediate results for each token.
Anyway, those activations are important for a couple of reasons:
- Each layer in the network takes input.
- Either the original embedding or the activations from the previous layer.
- It processes that input using its trained parameters.
- It produces new activations as output for the next layer.
- These activations must remain in memory until they are no longer needed in the current forward pass.
The memory required for activations scales roughly with:
- Number of tokens in the context window.
- Batch size: Scales linearly with more requests at once.
- Width of each hidden layer: the number of units in the intermediate representation for each token.
- Whether additional mechanisms like
attentionare applied.
So, for Phi-4, let’s assume:
- Batch size = 1
- Hidden size ≈ 12,000 units per token
- I’m not entirely sure about this number, Phi-4-multimodal-instruct seems to be the only model that is explict about it with 3072 units. But apparently GPT3 used 12,000 units, so let’s just roll with it for the moment.
- Context = 16,000 tokens
Then:
(👇 16-bit precision)
Activation memory per layer = 16,000 tokens x 12,000 hidden units x 2 bytes
≈ 384 MB
Since Phi-4 has 40 layers:
Total activation memory = 40 x 384 MB = 15.36 GB
Total Memory Estimate
Bringing it all together:
Parameters (BF16) = 29.4 GB
Activations (40 L) = 15.36 GB
--------------------------------
Total (V)RAM needed = 44.76 GB
This is a theoretical upper bound and is, as we will soon find out a gross overestimation. The actual requirement will vary depending on batch size, context length, and memory optimizations in the inference engine, but it illustrates why even small models like Phi-4 at 16-bit precision push memory limits really quickly.
GGUF MacGuffin
There’s also a phi-4-gguf variant. The GGUF format is designed specifically for efficient CPU-based inference — it enables features like layer offloading and supports multiple quantized versions of a model.
This is especially useful for Phi-4, since GGUF provides pre-quantized variants ranging from 16-bit all the way down to 1-bit. For CPU workloads, 4-bit quantization is generally regarded as the sweet spot, balancing memory savings, performance, and accuracy. That’s why I’ll be using the phi-4-Q4_K_S.gguf model, a 4-bit quantized version of Phi-4, in my benchmarks.
If you’ve browsed the model card, you’ll notice a long list of suffixes attached to each variant, which can look a bit arcane at first. These suffixes denote quantization schemes: different encoding strategies for compressing weights into fewer bits, each with trade-offs in speed, accuracy, and memory footprint.
Here’s a quick overview of the different 4-bit quantizations:
IQ4_XSQ4_K_SIQ4_NLQ4_0Q4_1
Great, but what does all of this mean:
Q4_0/Q4_1– The original 4-bit quantization methods; differ slightly in scaling strategy and accuracy (llama.cpp PR).Q4_K_*– Part of the newer k-quant family; designed to improve efficiency while retaining higher accuracy.IQ4_NL– Uses 32-weight blocks with fp16 scales, similar in size toQ4_0. The “NL” stands for non-linear (not near-lossless) (llama.cpp PR #5590).IQ4_*vsQ4_*– Both store weights as integers, but they differ in how scaling factors and offsets are applied.
For a full reference, HuggingFace’s GGUF: quantization-types documentation provides an excellent breakdown.
Downloading Quantized GGUF Models
To pull down Phi-4 in GGUF format, log in to HuggingFace and download the variants you need. For example, here’s how to grab both the BF16 (full precision) and Q4_K_S (4-bit) versions:
# Log into HuggingFace
hf auth login
# Or use a token directly (e.g. for CI/CD pipelines)
hf auth login --token $HF_TOKEN --add-to-git-credential
# Download BF16 and Q4_K_S quantized GGUF models
hf download microsoft/phi-4-gguf phi-4-bf16.gguf phi-4-Q4_K_S.gguf --local-dir ~
Running Phi-4 (BF16) on Cobalt 100
Even though the Arm Neoverse N2 CSS is capable of handling BF16, inference at full precision is going to be slow. But it’s worth running at least once to see what happens under the hood.
./llama-cli --model ~/phi-4-bf16.gguf \
--threads 64 \
--batch-size 128 \
--ctx-size 4096 \
--flash-attn on \
--mlock \
-p "Explain the theory of relativity in detail and include mathematical equations."
It helps to break down what these flags mean in practice. There are also manpages if you want the full reference.
| Flag | Meaning |
|---|---|
--model ~/phi-4-bf16.gguf | Path to your the model. |
--threads 64 | Total CPU threads used for inference. |
--threads-batch 64 | Number of threads allocated per batch in batched inference. |
--batch-size 128 | Token batch size per forward pass. |
--ctx-size 4096 | Context window size (number of tokens the model can remember). |
--flash-attn enabled | Use FlashAttention kernels if available (faster attention). |
--mlock | Pin model in RAM to avoid page swapping, using mlock(2). |
-p | The input prompt. |
A Databricks blog points out that “the Attention mechanism” in decoder-only models are computationally inefficient because each new token attends to all prior tokens. In practice, this is mitigated by KV caching (storing key/value tensors for reuse) and techniques like FlashAttention, which reduce memory movement and speed up long-context inference. Since Phi-4 is a dense decoder-only transformer, I’m not sure if enabling these optimizations helps stabilize throughput. We’ll soon see that performance was not bad, at least.
Before generating tokens, llama.cpp prints useful metadata about the model:
llama_model_loader: - type f32: 81 tensors
llama_model_loader: - type bf16: 162 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = BF16
print_info: file size = 27.31 GiB (16.00 BPW)
This shows that the model uses mixed precision: some tensors remain in FP32 (likely critical layers such as normalization or embeddings), while most are BF16 to save memory.
Then, llama.cpp reports the hardware features it will leverage:
CPU : NEON = 1 | ARM_FMA = 1 | FP16_VA = 1 | MATMUL_INT8 = 1 |
SVE = 1 | DOTPROD = 1 | SVE_CNT = 16 | OPENMP = 1 | REPACK = 1 |
Let’s look a bit closer at the hardware features it can use:
NEON = 1– SIMD acceleration available.ARM_FMA = 1– Hardware fused multiply-add.FP16_VA = 1– Vectorized FP16 math supported.MATMUL_INT8 = 1– Optimized int8 matmul kernels.SVE = 1/DOTPROD = 1/SVE_CNT = 16– Arm Neoverse N2 exposes Scalable Vector Extensions with 16 lanes and dot-product acceleration.OPENMP = 1– Multi-threading enabled.REPACK = 1– Tensor layouts are being repacked for better performance.
And then comes the fun part, the actual output of running Phi-4 BF16 on a Cobalt 100 CPU.
llama_perf_sampler_print: sampling time = 43.36 ms / 755 runs ( 0.06 ms per token, 17413.16 tokens per second)
llama_perf_context_print: load time = 3173.78 ms
llama_perf_context_print: prompt eval time = 5710.01 ms / 21 tokens ( 271.91 ms per token, 3.68 tokens per second)
llama_perf_context_print: eval time = 220719.37 ms / 733 runs ( 301.12 ms per token, 3.32 tokens per second)
llama_perf_context_print: total time = 467819.86 ms / 754 tokens
llama_perf_context_print: graphs reused = 730
That’s not very fast, but it is to be expected. Remember, you’re trading in accuracy for performance here. I didn’t really understand what the output meant so I wrote it down:
- Sampling: Token selection is trivially fast (0.06 ms/token).
- Model Load: Loading weights into memory takes a few seconds.
- Prompt Evaluation: First-pass tokens are slow since the entire transformer stack must process them.
- Generated Tokens: Main bottleneck — ~300 ms per token, or ~3.3 tokens/sec.
- Graph Reuse: llama.cpp reuses computation graphs across runs to reduce overhead.
One thing I did notice in tools like top and htop was the fact there was not as much memory being used. Remember we had that calculation where we predicted that we would be using 45GB of RAM. GGUF can use quantization and memory mapping. It may not load all weights fully into RAM immediately. Some parts are mapped to disk which further reducing peak RAM usage.
Memory Behavior
One surprise: memory usage was lower than expected. Based on parameter counts, we predicted ~45 GB RAM usage, but in practice llama.cpp reports:
lama_memory_breakdown_print: | memory breakdown [MiB] | total free self model context compute unaccounted |
llama_memory_breakdown_print: | - Host | 28820 = 27961 + 800 + 58 |
This shows ~28 GB “total”, but only 58 MiB attributed to the “model” column. Why?
- GGUF models are largely mmap’ed — the weights live on disk and are paged in as needed.
- Only the active slices of weights are loaded into RAM.
- The rest stays on disk, which dramatically reduces peak RAM consumption.
So while BF16 is compute-bound on CPU, memory mapping prevents it from being memory-bound.
Quantized Model
Switching to the quantized phi-4-Q4_K_S.gguf variant paints a very different picture:
llama_model_loader: - type f32: 81 tensors
llama_model_loader: - type q4_K: 156 tensors
llama_model_loader: - type q5_K: 5 tensors
llama_model_loader: - type q6_K: 1 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = Q4_K - Small
print_info: file size = 7.86 GiB (4.60 BPW)
...
llama_perf_sampler_print: sampling time = 43.60 ms / 842 runs ( 0.05 ms per token, 19312.37 tokens per second)
llama_perf_context_print: load time = 68278.95 ms
llama_perf_context_print: prompt eval time = 307.50 ms / 21 tokens ( 14.64 ms per token, 68.29 tokens per second)
llama_perf_context_print: eval time = 25009.02 ms / 820 runs ( 30.50 ms per token, 32.79 tokens per second)
llama_perf_context_print: total time = 64661.43 ms / 841 tokens
llama_perf_context_print: graphs reused = 816
...
llama_memory_breakdown_print: | memory breakdown [MiB] | total free self model context compute unaccounted |
llama_memory_breakdown_print: | - Host | 8904 = 8046 + 800 + 58 |
Some key differences compared to the BF16 run:
- Model size drops from ~27 GB to 7.86 GB.
- Throughput improves 10x, from ~3.3 tokens/s to 32.8 tokens/s.
- Prompt eval latency drops massively (271 ms/token to 14.6 ms/token).
- Memory usage falls to ~9 GB total, with only ~58 MiB of weights paged in.
This is where quantization starts to shine: compute is dramatically faster, and RAM/disk usage is far more practical.
Cross-Checking with llama-bench
Instead of relying only on llama-cli, we can benchmark with llama-bench (which has its own manpage):
~/llama.cpp/build/bin/llama-bench --model ~/phi-4-Q4_K_S.gguf \
--threads 64
-pg 256,1024
--output md
The results look familiar:
| model | size | params | backend | threads | test | t/s |
|---|---|---|---|---|---|---|
| phi3 14B Q4_K - Small | 7.86 GiB | 14.66 B | CPU | 64 | pp512 | 107.95 ± 0.03 |
| phi3 14B Q4_K - Small | 7.86 GiB | 14.66 B | CPU | 64 | tg128 | 34.00 ± 0.56 |
| phi3 14B Q4_K - Small | 7.86 GiB | 14.66 B | CPU | 64 | pp256+tg1024 | 31.13 ± 0.37 |
You can see the ~34 tokens/sec (tg128) result matches closely with what we got from llama-cli (~32.8 tokens/sec).
At first glance, pp512, tg128 and pp256+tg1024 look absurdly cryptic. But after reading in to this a little more, it turns out that they actually map to representative usage scenarios:
- pp512 – prompt processing: medium prompt, minimal output. Stresses input encoding (e.g., few-shot classification).
- tg128 – token generation: short prompt, short output. Stresses decoding (e.g., classification, keyword extraction).
- pp256+tg1024 – mixed load: short prompt, long output. Stresses full generative throughput (e.g., story writing, summarization).
Think of these as “synthetic workloads” that benchmark extremes: reading, writing, and combined usage.
Extending to Real-World Scenarios
I then began searching for what other possible combinations and how those can be used:
| Prompt tokens | Text Generation | Use cases |
|---|---|---|
| 16 | 1536 | Extreme expansion — story generation from a seed, creative writing, long draft from short idea. |
| 64 | 1024 | Short-to-long expansion — poetry, short prompt to long story, code autocompletion. |
| 384 | 1152 | Expansion / brainstorming — prompt expansion, explanations, creative text, code snippets. |
| 1024 | 16 | Classification / compression — sentiment, intent, keyword extraction, labeling. |
| 1024 | 1024 | Balanced generation — Q&A, blog/content drafting, code with explanations. |
| 1280 | 3072 | Reasoning + long generation — chain-of-thought, long-form creative writing, extended code. |
| 1536 | 1536 | Even balance (extended) — multi-turn dialogue, medium essays, structured drafting. |
| 2048 | 256 | Focused summarization — article summarization, synthesis, short contextual answers. |
| 2048 | 768 | Structured drafting — multi-paragraph replies, technical explanations, report sections. |
| 4096 | 256 | Context-heavy concise answers — RAG Q&A, legal/academic lookup, dense summaries. |
| 8192 | 64 | Extreme compression — long document classification, ultra-condensed summarization. |
| 8192 | 1024 | Long-context generation — book/chapter synthesis, RAG over large corpora, detailed reports. |
One rule of thumb however: ensure prompt_tokens + gen_tokens <= model_max_context. Many LLMs enforce a single combined window.
Batched benchmark
The llama.cpp repo also includes batched-bench, which goes beyond single-request testing and measures how well inference scales across multiple parallel sequences. It supports two distinct modes for handling prompts:
- Shared prompt mode
- Only one prompt is actually decoded, and its KV cache is copied across all sequences.
- Saves compute when many requests share the same context (e.g., multiple continuations of the same system prompt).
- Dramatically reduces prompt processing cost.
- Non-shared prompt mode (default)
- Each sequence has its own prompt processing.
- KV cache size scales linearly with number of sequences:
n_ctx_req = pl * (pp + tg). - Represents the “realistic” case where every request is independent.
At first I was a little confused because llama-bench and llama-batched-bench look nearly identical — both share the same command-line parsing, both accept --batch-size (n_batch) and --ubatch-size (n_ubatch). But their goals are different:
llama-bench- Measures performance of a single inference workload.
- Knobs: batch size (
n_batch), micro-batch (n_ubatch), prompt length, generation length. - No notion of parallel independent requests.
- Great for tuning throughput/latency trade-offs of one request.
llama-batched-bench- Adds another dimension:
n_pl, the number of parallel sequences. - Can run many independent requests simultaneously.
- Lets you test how performance scales across workloads, not just within one workload.
- Especially useful for server-like scenarios where multiple clients are querying at once.
- Adds another dimension:
Armed with that context, let’s actually run llama-batched-bench and see how throughput scales when we increase the number of sequences. We can now run the benchmark with multiple parallel sequences (npl), from 1 up to 16:
./llama-batched-bench --model ~/phi-4-Q4_K_S.gguf \
--threads 64 \
--threads-batch 64 \
--batch-size 128 \
-npp 128 \
-ntg 128 \
-npl 1,2,4,8,16 \
--ctx-size 4096 \
--flash-attn enabled \
--mlock \
--output-format md
In llama.cpp terminology:
- Sequence (
npl); one independent request (like a user session). - Batch: group of sequences processed together per forward pass.
By default, we’re in non-shared prompt mode, so memory and compute scale roughly linearly with number of sequences. Running npl=4 requires ~4x the KV memory compared to npl=1.
Let’s look at those input flags again.
| Flag | Meaning |
|---|---|
--model ~/phi-4-Q4_K_S.gguf | Path to your quantized model. |
--threads 64 | Total CPU threads used for inference. |
--threads-batch 64 | Number of threads allocated per batch in batched inference. |
--batch-size 128 | Token batch size per forward pass. |
-npp 128,256,512 | Number of prompt tokens to benchmark. Tests 128, 256, 512 tokens. |
-ntg 128 | Number of tokens to generate per benchmark. |
-npl 1,2,4,8,16 | Number of parallel sequences per batch. |
--ctx-size 4096 | Context window size (number of tokens the model can remember). |
--flash-attn enabled | Use FlashAttention kernels if available (faster attention). |
--mlock | Pin model in RAM to avoid page swapping, using mlock(2). |
--output-format md | Output results in Markdown table. |
The first couple of dozen of lines are related to infromation about the model itself.
llama_model_loader: - type f32: 81 tensors
llama_model_loader: - type q4_K: 156 tensors
llama_model_loader: - type q5_K: 5 tensors
llama_model_loader: - type q6_K: 1 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = Q4_K - Small
print_info: file size = 7.86 GiB (4.60 BPW)
Most tensors are quantized into Q4_K small blocks, with a few remaining in q5/q6/f32 for stability.
- Q4_K-Small = fastest, smallest footprint, lower accuracy than Medium/Large.
- Model fits in ~8 GiB instead of 28 GiB (the bf16 version).
Small indicates small-sized blocks are used for quantization. You can also have Medium or Large-sized blocks. This ties into the memory size, speed and accuracy story. Small gives you the smallest precision, it’s the fastest but has lower accuracy.
Once the model is loaded, llama.cpp constructs the runtime context. Here’s the relevant log section:
...................................................................................
llama_context: constructing llama_context
llama_context: n_seq_max = 16
llama_context: n_ctx = 4096
llama_context: n_ctx_per_seq = 256
llama_context: n_batch = 128
llama_context: n_ubatch = 128
llama_context: causal_attn = 1
llama_context: flash_attn = enabled
llama_context: kv_unified = false
llama_context: freq_base = 250000.0
llama_context: freq_scale = 1
llama_context: n_ctx_per_seq (256) < n_ctx_train (16384) -- the full capacity of the model will not be utilized
llama_context: CPU output buffer size = 6.12 MiB
llama_kv_cache: CPU KV buffer size = 800.00 MiB
llama_kv_cache: size = 800.00 MiB ( 256 cells, 40 layers, 16/16 seqs), K (f16): 400.00 MiB, V (f16): 400.00 MiB
llama_context: CPU compute buffer size = 57.50 MiB
llama_context: graph nodes = 1167
llama_context: graph splits = 1
Here you can see:
- We asked for
-npl 16, so the runtime sets up space for 16 parallel sequences (n_seq_max = 16). - With a global context size of
4096, each sequence only gets 256 tokens of usable context (n_ctx_per_seq = 256). - The KV cache is the largest consumer of memory here:
800 MiBtotal, split evenly between Keys (400 MiB) and Values (400 MiB) across 40 transformer layers and all 16 sequences. - Buffers for outputs (6.1 MiB) and compute scratch space (57.5 MiB) are relatively tiny in comparison.
n_ctx_per_seq (256) < n_ctx_train (16384) means that the model was trained with a 16k context, but we’re benchmarking with much smaller windows. That’s fine for stress tests.
KV Cache and Autoregressive Generation
Language models generate text one token at a time, each step depending on everything that came before. This is called autoregressive generation.
Without optimizations, the model would need to recompute the full forward pass over all tokens for every new output token — which would be extremely slow. To prevent this, LLMs use a Key-Value (KV) cache.
- As the model processes tokens, it computes intermediate states (the Keys and Values) used by the attention mechanism.
- These are stored in memory (RAM or VRAM).
- When generating the next token, the model simply looks up and reuses these cached states instead of recalculating them from scratch.
This trick makes autoregressive generation feasible at scale — but it comes at a memory cost.
What drives KV cache size?
- Sequence length: The more tokens in the prompt or output, the more cache entries must be stored.
- Batch size: Each sequence in a batch needs its own KV cache. Larger batches multiply memory use.
- Model architecture: Wider hidden layers and more attention heads increase the size of each Key and Value.
In practice, the KV cache can grow surprisingly large — for long contexts or high batch sizes, it may even rival the size of the model’s weights. This is why running inference with long context windows often requires much more memory than just the model file size would suggest.
Batched benchmark: Results
And in our run, here’s how the results played out…
main: n_kv_max = 4096, n_batch = 128, n_ubatch = 512, flash_attn = 1, is_pp_shared = 0, n_gpu_layers = -1, n_threads = 64, n_threads_batch = 64
| PP | TG | B | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | T s | S t/s |
|-------|--------|------|--------|----------|----------|----------|----------|----------|----------|
| 128 | 128 | 1 | 256 | 1.232 | 103.87 | 3.800 | 33.68 | 5.033 | 50.87 |
| 128 | 128 | 2 | 512 | 2.306 | 111.02 | 4.325 | 59.19 | 6.631 | 77.21 |
| 128 | 128 | 4 | 1024 | 4.652 | 110.06 | 7.070 | 72.42 | 11.722 | 87.36 |
| 128 | 128 | 8 | 2048 | 9.249 | 110.72 | 12.070 | 84.84 | 21.318 | 96.07 |
| 128 | 128 | 16 | 4096 | 18.495 | 110.73 | 22.206 | 92.23 | 40.701 | 100.64 |
Let’s render that markdown table here:
| PP | TG | B | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | T s | S t/s |
|---|---|---|---|---|---|---|---|---|---|
| 128 | 128 | 1 | 256 | 1.232 | 103.87 | 3.800 | 33.68 | 5.033 | 50.87 |
| 128 | 128 | 2 | 512 | 2.306 | 111.02 | 4.325 | 59.19 | 6.631 | 77.21 |
| 128 | 128 | 4 | 1024 | 4.652 | 110.06 | 7.070 | 72.42 | 11.722 | 87.36 |
| 128 | 128 | 8 | 2048 | 9.249 | 110.72 | 12.070 | 84.84 | 21.318 | 96.07 |
| 128 | 128 | 16 | 4096 | 18.495 | 110.73 | 22.206 | 92.23 | 40.701 | 100.64 |
We should try to understand what is it we’ve been presented with. Here’s what I’ve been able to gather:
| Column | Meaning | Notes / How it’s calculated |
|---|---|---|
| PP | Prompt tokens per batch | Number of prompt tokens in each batch. |
| TG | Generated tokens per batch | Number of tokens the model generates per batch. |
| B | Number of batches | How many batches were processed in this measurement. |
| N_KV | Required KV cache size | Number of key/value entries needed for attention during this batch. |
| T_PP s | Prompt processing time | Time spent processing all prompt tokens (i.e., time to first generated token). |
| S_PP t/s | Prompt processing speed | Throughput for prompts: PP / T_PP or (B × PP) / T_PP |
| T_TG s | Time to generate all batches | Total time spent generating tokens for all batches. |
| S_TG t/s | Text generation speed | Throughput for generated tokens: (B*TG) / T_TG |
| T s | Total time | Sum of T_PP and T_TG. |
| S t/s | Total speed | Overall throughput: all tokens / total time. |
Why does the throughput scale this way? Apparently, throughput improves with larger batch sizes, but the scaling is sublinear.
- At batch = 1, the compute routines is only working on a single input vector. This underutilizes the CPU’s SIMD units and threading capacity.
- At batch = 16, the compute routines can fuse operations across 16 sequences, processing them in the same matrix multiply. This lets SIMD and parallelization kick in fully, giving better throughput.
However, bigger batches come with trade-offs:
- Larger KV caches eat up memory (see
N_KVgrowing from 256 to 4096). - Scheduling overhead grows as more sequences are juggled in parallel.
The net result:
- Prompt processing speed (
S_PP) stays roughly flat (~110 tokens/sec). - Generation throughput (
S_TG) steadily climbs (33 to 92 tokens/sec). - Total throughput (
S t/s) nearly doubles (51 to 101 tokens/sec), but not linearly.
So batching helps efficiency, but you don’t get a free 16x speedup with 16x batches; you get roughly ~2x instead. On a Standard_D64ps_v6 with Phi-4 Q4_K_S, the system topped out around 100 tokens/sec. For CPU-only inference, that’s very solid, though still far behind GPUs, which can push into the thousands of tokens/sec.
Other benchmarks
Meta-Llama-3-8B-Instruct (Q4_0)
Arm themselves have also published quite a few benchmarks. One that stood out was their run of Llama-3-70B on AWS Graviton4 (Neoverse V2). In their October 2024 write-up, they mentioned targeting a readability SLA of 5–10 tokens per second.
At first that looked low to me — I’m used to how snappy AI assistants feel — but it makes sense: 10 tokens/sec actually beats human reading speed, so for many use cases it’s “good enough.”
To compare directly, I ran my own tests using the exact same QuantFactory/Meta-Llama-3-8B-Instruct.Q4_0 model with the same llama-batched-bench settings as before.
| VM | Processor | PP | TG | B | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | T s | S t/s |
|---|---|---|---|---|---|---|---|---|---|---|---|
| D64ps_v6 | Cobalt 100 | 128 | 128 | 1 | 256 | 0.216 | 591.60 | 2.134 | 59.99 | 2.350 | 108.93 |
| D64ps_v6 | Cobalt 100 | 128 | 128 | 2 | 512 | 0.412 | 620.62 | 3.205 | 79.87 | 3.618 | 141.53 |
| D64ps_v6 | Cobalt 100 | 128 | 128 | 4 | 1024 | 0.827 | 618.92 | 2.971 | 172.31 | 3.799 | 269.57 |
| D64ps_v6 | Cobalt 100 | 128 | 128 | 8 | 2048 | 1.683 | 608.52 | 4.535 | 225.79 | 6.218 | 329.37 |
| D64ps_v6 | Cobalt 100 | 128 | 128 | 16 | 4096 | 3.305 | 619.59 | 5.862 | 349.39 | 9.167 | 446.82 |
| D64as_v6 | EPYC 9004 | 128 | 128 | 1 | 256 | 0.413 | 309.73 | 4.570 | 28.01 | 4.983 | 51.37 |
| D64as_v6 | EPYC 9004 | 128 | 128 | 2 | 512 | 0.812 | 315.40 | 5.287 | 48.42 | 6.099 | 83.95 |
| D64as_v6 | EPYC 9004 | 128 | 128 | 4 | 1024 | 1.623 | 315.48 | 5.415 | 94.56 | 7.038 | 145.50 |
| D64as_v6 | EPYC 9004 | 128 | 128 | 8 | 2048 | 3.246 | 315.46 | 7.442 | 137.60 | 10.688 | 191.62 |
| D64as_v6 | EPYC 9004 | 128 | 128 | 16 | 4096 | 6.491 | 315.50 | 9.964 | 205.55 | 16.455 | 248.92 |
| D64s_v6 | Xeon Platinum 8573C | 128 | 128 | 1 | 256 | 0.329 | 388.91 | 3.039 | 42.12 | 3.368 | 76.01 |
| D64s_v6 | Xeon Platinum 8573C | 128 | 128 | 2 | 512 | 0.662 | 386.79 | 3.471 | 73.76 | 4.133 | 123.89 |
| D64s_v6 | Xeon Platinum 8573C | 128 | 128 | 4 | 1024 | 1.315 | 389.26 | 4.010 | 127.68 | 5.325 | 192.29 |
| D64s_v6 | Xeon Platinum 8573C | 128 | 128 | 8 | 2048 | 2.615 | 391.62 | 4.942 | 207.21 | 7.557 | 271.02 |
| D64s_v6 | Xeon Platinum 8573C | 128 | 128 | 16 | 4096 | 5.241 | 390.76 | 7.903 | 259.14 | 13.144 | 311.62 |
With 16 concurrent requests (batch=16), I sustained ~446 tokens/sec total output across users on Azure’s Standard_D64ps_v6 (Cobalt 100 / Neoverse N2). The EPYC 9004 (Genoa) held its own with a respectable ~249 tokens/sec total output, but is roughly USD 610 (31%) more expensive. The Xeon Platinum 8573C (Emerald Rapid) was able to crunch ~312 tokens/sec total output is roughly USD 860 (44%) more expensive.
llama-3.2-3b-instruct (Q4_0)
I also tested llama-3.2-3b-instruct.Q4_0 on Standard_D64ps_v6 (Neoverse N2), using the same llama-bench command as AWS Builders in their Graviton4 benchmark write-up:
~/llama.cpp/build/bin/llama-bench -m ~/llama-3.2-3b-instruct.Q4_0.gguf -pg 256,1024 -t 64 -o md
The results were close to the published AWS Graviton3 (c7g.16xlarge, Neoverse V1) numbers. I also ran these tests on the x86_64 counterparts to get an idea of how well things were going.
| VM | Processor | test | t/s |
|---|---|---|---|
| D64ps_v6 | Cobalt 100 | pp512 | 1274.58 ± 4.14 |
| D64ps_v6 | Cobalt 100 | tg128 | 95.23 ± 2.18 |
| D64ps_v6 | Cobalt 100 | pp256+tg1024 | 99.39 ± 0.77 |
| D64as_v6 | EPYC 9004 | pp512 | 579.32 ± 0.31 |
| D64as_v6 | EPYC 9004 | tg128 | 58.94 ± 0.21 |
| D64as_v6 | EPYC 9004 | pp256+tg1024 | 66.06 ± 0.13 |
| D64s_v6 | Xeon Platinum 8573C | pp512 | 580.61 ± 0.84 |
| D64s_v6 | Xeon Platinum 8573C | tg128 | 79.96 ± 0.60 |
| D64s_v6 | Xeon Platinum 8573C | pp256+tg1024 | 84.80 ± 0.13 |
Takeaways: Benchmarks, Best Practices and Emissions
GPUs are still the clear leaders for high-throughput, latency-sensitive inference, but the tradeoffs are worth highlighting:
- Many GPU-enabled NC-series VMs now come with multiple accelerators per instance, which drives up PAYG costs.
- CPU-based instances like
D64ps_v6(Cobalt 100) andD64as_v6(EPYC 9004) are slower, but more predictable and sometimes cheaper for batch-oriented workloads. - Azure AI Foundry’s sidesteps infrastructure entirely with per-token pricing.
For context, here are (some more) current West Europe PAYG rates (no reserved discounts):
- Standard_NC4as_T4_v3: $480.34 — 1x NVIDIA T4 (16 GB VRAM, 4 CPU cores)
- Standard_D64ps_v6: $1,957.86 — Azure Cobalt 100 (Neoverse N2)
- Standard_D64as_v6: $2,565.22 — AMD EPYC 9004
- Standard_D64s_v6: $2,820.72 — Xeon Platinum 8573C
- Standard_NC24ads_A100_v4: $3,485.75 — 1x NVIDIA A100
- Standard_NC40ads_H100_v5: $6,628.40 — 1x NVIDIA H100
- Phi-4 (Preview) in Azure AI Foundry: $0.22 / 1M tokens (input + output)
🔥 Warning
The Tesla T4 (NCasT4_v3) does work with llama.cpp, but not vLLM. Its 16 GB VRAM is tight for modern models, and the instance only ships with 4 CPU cores. However, there is a variant with 4x T4 accelerators and 64 CPU cores! That makes it a bit awkward: it’s cheap and GPU-backed VM SKU, but with limits that make it a questionable long-term choice if you want engine flexibility.
x86_64 or Arm based CPUs?
Let’s get one thing out of the way: AI inference workloads are not limited to Arm. You can run them effectively on x86_64 (Intel/AMD) as well. But the choice is more nuanced than a simple Arm vs. x86_64 showdown. You need to weigh user experience, cost, performance-per-watt and (increasingly) carbon footprint.
Here’s the rough breakdown today:
- x64 (Intel/AMD) – Best for legacy workloads and broad ecosystem support.
- Arm VMs – Excellent for general-purpose workloads (if your software stack is compatible). Usually lower cost and lower emissions.
- GPUs / accelerators – Essential for medium-to-large AI inference. High peak power draw, but much better efficiency per request.
- Hybrid approach – Run general workloads on Arm, inference on GPUs. Clouds like Azure make this easy (e.g. AKS with mixed node pools).
That said, the competitive landscape is shifting:
- Intel is pushing efficiency with its 18A fabrication process, claiming 15% better performance-per-watt and 30% better density over Intel 3.
- AMD is scaling core counts aggressively. Its Bergamo EPYC 97xx (128 cores) claims ~2.9x the average performance of Ampere’s Altra Max, though at nearly double the TDP (360–400 W vs. 182 W).
💡 Note
Don’t think of this as “Arm vs. x86_64”…
Think “microarchitecture vs. microarchitecture”". The ISA seems to be largely irrelevant in the performance-per-watt discussion today. Arm has a lead in design choices (efficiency-first, license model), but x86_64 is evolving fast, especially with new instruction sets and high-core-count silicon.
This may not flip the efficiency narrative overnight, but it does mean the “Arm always wins on perf/watt” story is getting more complicated. And companies that have already gone all-in on Arm aren’t likely to reverse course unless performance/watt gaps become both obvious and widely discussed.
What about x86_64 for inference?
Inference is not just possible but effective on x86_64, provided the CPU supports vector and AI acceleration instructions:
- AVX/AVX2/AVX-512 (Advanced Vector Extensions)
- VNNI (Vector Neural Network Instructions)
- BF16 (bfloat16 for mixed-precision ML)
- APX and AVX10 in newer generations
For example, Intel Sapphire Rapids and Granite Rapids both support AVX10, AVX-512, VNNI, and BF16, which makes them surprisingly capable inference platforms for smaller to mid-size models.
Having said that, the results from my benchmarks speak for themselves. It’s certainly possible, but it doesn’t look like it’s a great value for money option (for now?).
Does ISA actually matter?
This was my biggest misconception. I assumed ISA differences explained why Arm had better performance-per-watt. Turns out, this is not really the case any more.
- Research going back to 2013 shows ISA itself doesn’t make a meaningful difference in power consumption.
- Modern CPUs, both Arm and x86_64, borrow design ideas from each other.
- What really matters:
- Microarchitecture (execution engine, cache hierarchy, scheduling, pipelines)
- Design choices (TDP envelope, manufacturing process, target workloads)
As Chips and Cheese notes: *ISA doesn’t matter, microarchitecture does.
Microarchitecture is the specific hardware implementation of a processor’s instruction set architecture (ISA), detailing how components like the control unit, arithmetic logic unit (ALU), registers and memory hierarchy are arranged to execute instructions. Different microarchitectures can implement the same ISA, but with different trade-offs in speed and power consumption.
Why does Arm feel different?
To wrap this up, I think I can answer this by concluding that Arm has earned its “excellent perf/watt” reputation (compared to x86_64) because its architectural licensing and energy-efficient designs allow companies like Apple, Amazon, Google and Microsoft to build custom chips optimized for their software stacks. Modern Arm-based server CPUs (such as Cobalt 100, Graviton, Altra Max, and Axion) focus on high core counts, lean pipelines and power-efficient microarchitectures.
Intel and AMD do make custom silicon (e.g. AMD’s APUs for gaming consoles, Intel Foundry for customers), and Intel Foundry can even manufacture Arm chips. However, Arm’s open licensing model, combined with its flexible designs and energy-efficient architecture, is a key reason it has traction with those hyperscalers.
Measuring and reducing carbon emissions
When choosing between SKUs, performance-per-watt is going to matter more and more. Cutting costs has always been a driver, but in the near future enterprises will also need to cut carbon emissions — and not just because it looks good in a sustainability report.
In the EU especially, regulation is moving quickly. A number of directives and policies are already in place or being phased in that will push both cloud providers and their customers to measure, report, and reduce emissions tied to datacenter use:
- Corporate Sustainability Reporting Directive (CSRD) : Large and listed companies must disclose GHG emissions, environmental, and social risks (phased rollout from 2024). This includes Scope 3 emissions (i.e. upstream data from providers), which might turn out to be important in the coming years.
- Energy Efficiency Directive (EED, revised): Data centers ≥500 kW must report metrics like PUE, renewable energy use, and water consumption. Customers may request this data to meet their own reporting needs.
- Ecodesign Regulation (EU 2019/424): Sets efficiency standards for servers and storage, ensuring cloud hardware meets baseline energy benchmarks.
- EU Taxonomy & Climate Delegated Acts: Defines criteria for what counts as “sustainable” economic activity, including data centers. Providers (and their customers) can be judged or rewarded based on alignment.
- EU Code of Conduct for Data Centre Energy Efficiency: Voluntary best practices (cooling, waste heat reuse, renewables) that often feed into taxonomy/regulatory assessments.
- Corporate Sustainability Due Diligence Directive (CSDDD): Requires companies to prevent environmental and human rights harms across their value chain, which extends to cloud/IT suppliers.
Of these, I get a sense that CSRD is likely to have the broadest impact. Since it covers Scope 3 emissions (all indirect emissions up and down the supply chain), enterprises will need accurate reporting from cloud vendors. For context:
- Scope 1 = direct emissions (e.g. burning fuel onsite)
- Scope 2 = purchased electricity
- Scope 3 = everything else in the value chain (cloud infrastructure, business travel, supply chain, etc.)
- Your Azure Public Cloud enviroment will fit perfectly in this category.
This means customers, not just data center operators, will be under pressure to track and reduce cloud-related emissions.
The good news is that tooling is starting to catch up. On Azure, the Carbon optimization service already helps enterprises measure and optimize the carbon impact of their workloads.
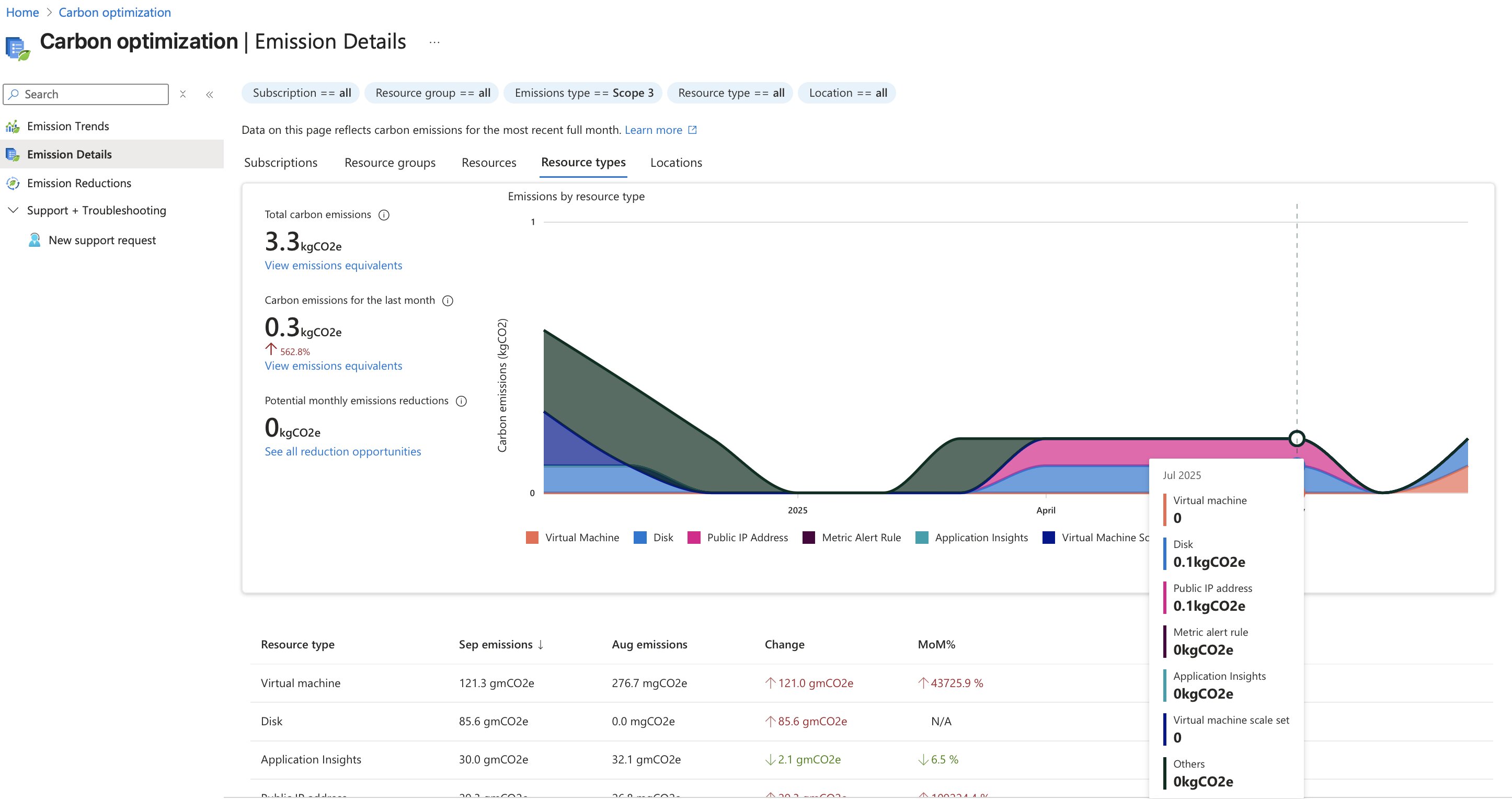
To me it looks inevitable that, over time, performance-per-watt, carbon intensity and compliance reporting will become first-class decision factors when choosing between instance types.
RISC-V on the horizon
Arm faces some interesting challenges ahead. Hyperscalers may push for more favorable licensing deals, which could put pressure on Arm’s business model. At the same time, the rise of RISC-V presents a new open-source alternative that could shake up the market, especially in the context of open-source disruption and hyperscaler vertical integration.
What is the licence model?
The RISC-V ISA is free and open with a permissive license for use by anyone in all types of implementations. Designers are free to develop proprietary or open source implementations for commercial or other exploitations as they see fit. RISC-V International encourages all implementations that are compliant to the specifications.
Note that the use of the RISC-V trademark requires a license which is granted to members of RISC-V International for use with compliant implementations. The RISC-V specification is based around a structure which allows flexibility with modular extensions and additional custom instructions/extensions. If an implementation was based on the RISC-V specification but includes modifications beyond this framework, then it cannot be referenced as RISC-V.
Does that mean free for industry to use and play with, but then we pay if we produce a product using this ISA?
There is no fee to use the RISC-V ISA. Those who want to use the RISC-V logo should join RISC-V International. To create an implementation from the RISC-V ISA, it is necessary to procure or leverage additional IP outside of RISC-V which may carry a fee. The RISC-V ISA alone is not an implementation.
This open model offers tremendous strategic flexibility. It allows organizations, anything from startups to hyperscalers, to design CPUs tailored to their own workloads without being locked into proprietary ISAs. History shows that big tech isn’t afraid to switch architectures when the benefits are clear—Apple has done it more than once, and others will too. With its blend of openness and customization, RISC-V could become the next chapter in that story. It’s an exciting space to watch… Because in technology, never say never.
Retro
Running your own inference infrastructure isn’t trivial. On one hand, Azure makes it almost effortless—you can hit a REST API and get results. On the other hand, if you actually want to understand what’s happening behind the scenes, you’re in for a deep dive.
I spent about two months worth of evenings experimenting with CPU inference, and I quickly realized there’s a ton guidance out there, albeit very scattered. Microsoft Learn and the Azure Architecture Center have a few notes on self-hosting models via KAITO on AKS or performance testing on HPC setups, but no full reference architectures exist for running AI workloads on CPUs. That meant I had to piece things together myself, in trial and error fashion.
Even now, I feel like this write-up only really scratches the surface and is missing quite a bit of nuance. There are still operational details to explore: model hosting, security, deployment best practices. And benchmarking? Forget about a standard test. Everyone, including me, seems to wing it with their own methods, which makes it tricky to know if your results are actually good.
One thing I’ll be watching closely is BitNet, especially v2. It’s still research-only, but it’s fascinating: ternary weights (−1, 0, +1, ~1.58 bits each) and 4-bit activations shrink memory and simplify computation. In theory, multiplication becomes just add/negate/zero operations. This could make large models fit into smaller memory footprints, especially if combined with Mixture-of-Experts designs.
For anyone diving into quantization, I can’t recommend enough Maarten Grootendorst’s blog post (A Visual Guide to Quantization) and book he wrote with with Jay Alammar. They give engineers a clear look at what’s happening inside LLMs. Lilian Weng also keeps an up-to-date series of blog posts that are incredibly insightful for understanding LLM internals.
Finally, the engineering blogs from Databricks and NVIDIA are great, too. They dive into batching strategies, trade-offs between batch size and latency, and general performance optimization. While I wish the community would standardize these benchmarks, the reality is every setup is different. So for now, experimentation is part of the game.
At the end of the day, self-hosting AI is kind of like exploring a jungle. There seems to be no single path, a lot to learn along the way and the deeper you go, the more you realize there’s always another rabbit hole waiting. But it’s also rewarding: you gain a level of insight that’s impossible to get from a managed API alone!
Further reading on Arm inference
- Arm LLM optimizations – Highly Optimized Kernels and Fine-Grained Codebooks for LLM Inference on Arm CPUs (arXiv 2025)
- AWS Graviton & llama.cpp – Running Llama.cpp on Graviton (GitHub)
- Google Axion CPU – AI inference on Google Axion (Arm blog)
- Arm Neoverse N2 – Accelerated LLM inference on Neoverse N2 (Arm blog)
- AI inference everywhere – Llama models on Arm (Arm newsroom)
- Why smaller models matter – The case for small language model inference on Arm CPUs (Arcee.ai)
- Tags |
- Azure
- Compute
- Ai
- Governance
Related posts
- Making Sense of AI
- Azure Confidential Computing: Confidential GPUs and AI
- Microsoft Entra Privileged Identity Management (for Azure Resources) Revisited
- Azure Linux OS Guard on Azure Kubernetes Service
- Windows Containers: Azure Pipeline Agents with Entra Workload ID in Azure Kubernetes Service
- Register Azure Pipeline Agents using Entra Workload ID on Azure Kubernetes Service
- Azure Confidential Computing: CoCo - Confidential Containers
- Azure Confidential Computing: Confidential Temp Disk Encryption
- Azure Confidential Computing: Secure Key Release - Part 2
- Azure Confidential Computing: Microsoft Azure Attestation
- Azure Confidential Computing: Azure RBAC for Secure Key Release
- Azure Confidential Computing: Verifying Microsoft Azure Attestation JWT tokens
- Azure Confidential Computing: Secure Key Release
- Azure Confidential Computing: Confidential VMs
- Azure Confidential Computing: IaaS