Azure Confidential Computing: Confidential GPUs and AI
In this post
Welcome to the AI Boom. 👋
You can’t escape it, I certainly can’t. AI is everywhere, reshaping industries, workflows, and our expectations of what’s possible. I get the appeal—it’s unlocking solutions to problems that were once nightmares from an algorithmic standpoint. Things that used to be hard are now surprisingly accessible, even in typically risk-aversive enterprise environments, and are often integrated into business workflows at lightning speed as companies strive to provide anything that uses AI.
For a while, I’ve been watching the confidential computing space, waiting to see how things unfold. Confidential GPUs—and by extension, confidential AI—have been on my radar, but I initially assumed they’d be yet another difficult thing to learn. Turns out, I was wrong. From what I’ve gathered, confidential GPUs follow a familiar path, mirroring how Confidential Computing has been evolving on the CPU side.
At a high level, the way confidential VMs and confidential GPUs work together is refreshingly straightforward. It builds on the same principles I’ve explored in Confidential Computing over the years: encrypting data at various layers of hardware and ensuring that workloads run only in trusted environments through cryptographic attestation.
In short, it’s all about keeping your AI workloads encrypted while they’re running.
New to Confidential Computing?
Confidential computing solutions center around “attestable”, “hardware-based Trusted Execution Environments” (TEEs). These TEEs provide isolated environments with enhanced security, preventing unauthorized access or modification of applications and data while in use. Typically, a TEE has at least provides the following three properties:
- Data confidentiality: Data within the TEE remains inaccessible to unauthorized entities.
- Data integrity: Unauthorized entities cannot tamper with data within the TEE.
- Code integrity: Unauthorized entities cannot modify the code running within the TEE.
Confidential Computing primarily comes in two flavors: process-based and virtual machine-based isolation.
- Process-based isolation: often associated with the term “enclave,” encloses the isolation boundary around each container process. While this offers precision, adapting applications to run within this boundary may require code adjustments. Intel Software Guard Extensions (SGX) is a technology that lets you create these enclaves.
- Virtual machine-based isolation: encompasses the boundary around a virtual machine, allowing for more flexibility when migrating existing workloads into confidential computing environments. The downside of this is that you will have many more individual components that you will need to place your trust in. AMD SEV-SNP and Intel Trust Domain Extensions (TDX) are two technologies that let you use this isolation model.
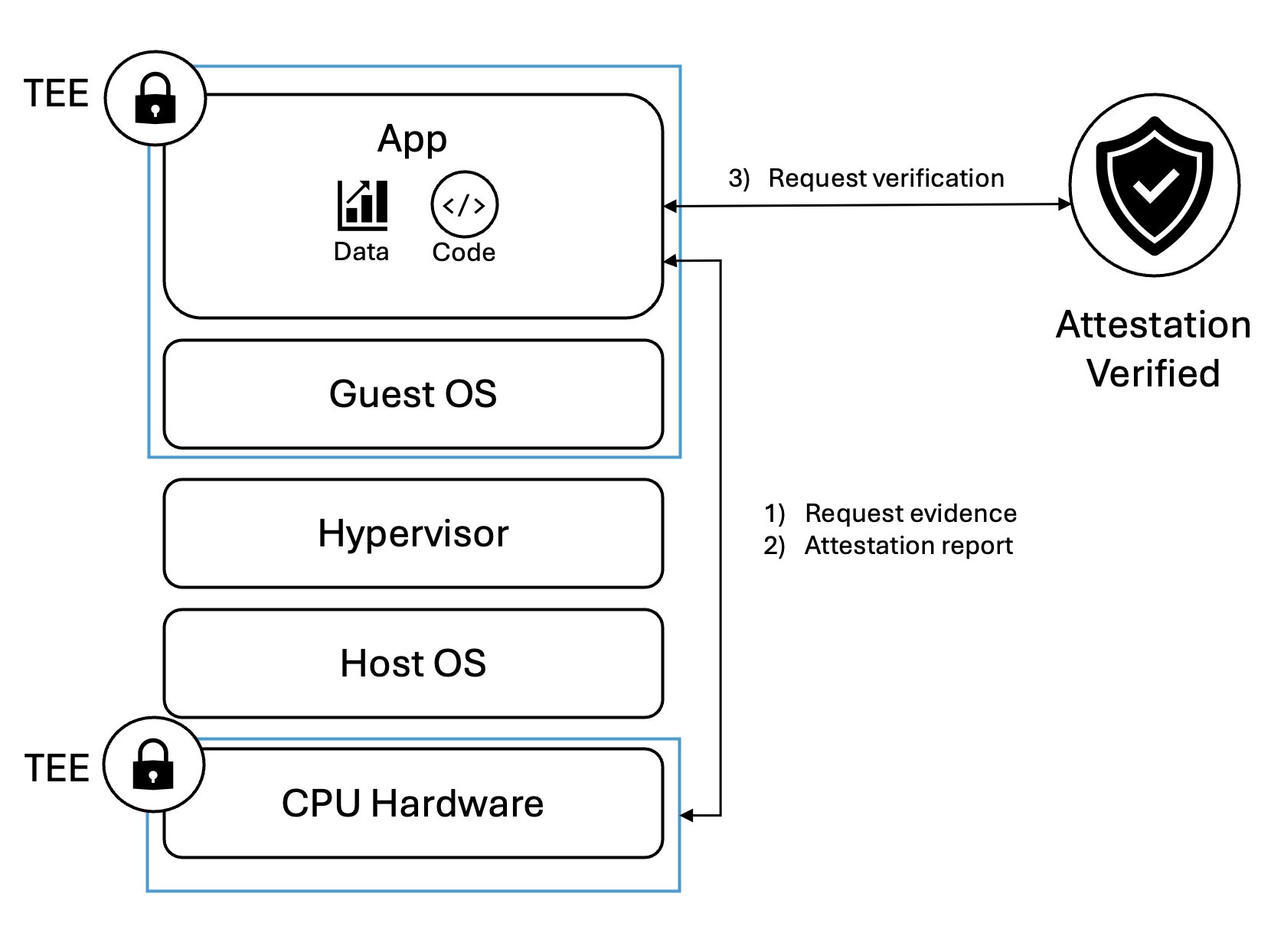
One of the most critical aspects of Confidential Computing is attestation. TEEs are built from the ground up to be cryptographically verifiable, meaning you (as the user) can prove that your environment is running in a trusted state before launching your workloads. This process involves certificate chains, JWT signatures, and other security mechanisms to verify that your compute environment is what it claims to be.
💡 If you’re entirely new to Azure Confidential Computing or need a refresher, check out my previous articles or sessions on this topic:
Why Are Confidential GPUs Important?
It’s funny—many of the same reasons you’d want to use confidential computing in the first place also apply to Confidential GPUs and Confidential AI.
There are enterprises—especially in regulated industries—demanding strong confidentiality guarantees for AI workloads running on GPUs. These organizations need end-to-end, verifiable data privacy, even from cloud providers and infrastructure operators. They want to extend security beyond just encrypting data at rest and in transit, ensuring that data remains private even while being processed. This is exactly what Confidential Computing is designed for—provided it’s used correctly.
💡 Reminder
Strong confidentiality guarantees mean that “Data within the Trusted Execution Environment remains inaccessible to unauthorized entities.”
Here are a few real-world scenarios, where this type of technology might make sense:
- A company has an AI model with proprietary weights representing valuable intellectual property. Keeping those weights secure is a top priority.
- A multi-party computation scenario: Imagine hospitals collaborating on medical research. Each has sensitive patient data, but they can only unlock valuable insights by securely performing computations across datasets. They must ensure data privacy while sharing results.
- Preventing privileged insiders from accessing GPU memory: The last thing you want is a cloud administrator—or even a malicious insider—dumping memory from a hypervisor and extracting sensitive model data or GPU computations.
🤔 “Just how viable is this attack vector?”
Dumping a VM’s running memory isn’t trivial. But history has shown that it’s far from impossible.
Take the Storm-0558 attack, where a China-based threat actor obtained a Microsoft account signing key, likely from an old crash dump of a running VM. That stolen key was used to forge authentication tokens and access Microsoft services like Outlook. If the crash dump’s contents had been encrypted, the attacker might never have extracted the key.
Events like these have accelerated the push for Confidential Computing, including initiatives like Microsoft’s Secure Future Initiative (SFI) for stronger enterprise security.
The Importance of a Small Trusted Computing Base
Choosing the right Confidential Computing solution requires evaluating your Trusted Computing Base (TCB), which is the total set of hardware, firmware, and software components that must be trusted to maintain security. The smaller your TCB, the lower your exposure to vulnerabilities, malware, and insider threats.
🔥 Warning
If any component within the TCB is compromised, the security of the entire system is at risk.
Here’s how the TCB compares across different Confidential Computing solutions:
| Without CC | CC w/ Intel SGX | CC w/ CVMs (SEV-SNP/TDX) | CC w/ CVMs & CGPUs | |
|---|---|---|---|---|
| Infrastructure Owner | ✅ | ❌ | ❌ | ❌ |
| Hardware | ✅ | ✅ | ✅ | ✅ |
| BIOS, Device Drivers | ✅ | ❌ | ❌ | ❌ |
| Hypervisor | ✅ | ❌ | ❌ | ❌ |
| Host OS | ✅ | ❌ | ❌ | ❌ |
| VM Guest admins | ✅ | ❌ | ✅ | ✅ |
| Guest OS | ✅ | ❌ | ✅ | ✅ |
| Shared libraries | ✅ | ❌ | ✅ | ✅ |
| Application | ✅ | ✅ | ✅ | ✅ |
While there’s no explicit Azure documentation stating this, I’m going to assume that the TCB for Confidential GPUs is very close to that of CVMs—just with the GPU added to the trust boundary. You’d typically opt for the CVM approach when compliance requirements dictate that “Microsoft cannot access anything running inside my virtual machine, but I do trust the OS, everything running inside of it, and my own VM’s administrators.”
Confidential GPUs extend this concept further. They keep those confidentiality guarantees while data is in-use on the GPU, this makes is so that even GPU memory is part of the Trusted Execution Environment. For example, if a malicious Azure admin were to dump the memory of a running VM or extract GPU contents from outside the TEE boundary, all they’d get is encrypted data—completely useless without the decryption keys.
How Confidential GPUs Work
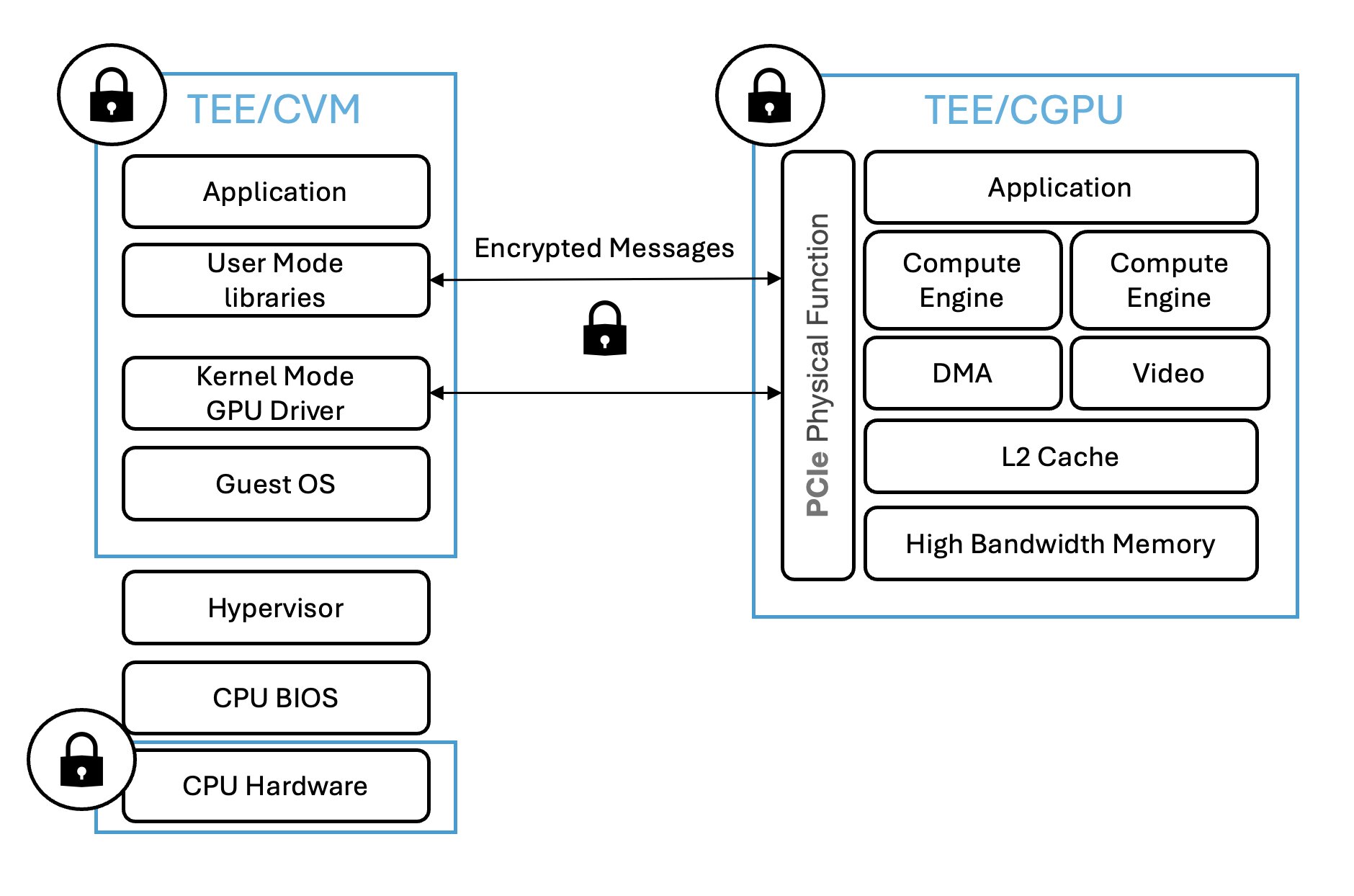
At a high level, confidential GPUs enable secure offloading of data, models, and computation to the GPU all while maintaining encryption throughout the process. In a nutshell, here’s what it encompasses:
- All code, data (including model weights, prompts, and outputs), and cryptographic keys remain encrypted in CPU memory.
- When data moves between the CPU and GPU over the PCIe bus, it stays encrypted.
- The only place data is decrypted is within the CPU package and the High-Bandwidth Memory (HBM) inside the GPU.
- Even privileged access (e.g., cloud administrators) cannot extract decrypted data from the GPU due to hardware-enforced security boundaries.
According to NVIDIA, you do not need to change your code (in most cases) in order to make use of the H100’s confidential computing mode. In terms of performance, when you have confidential computing mode enabled, the following performance aspects match those of non-confidential mode:
- GPU raw compute performance: The compute engines process plaintext code on plaintext data in GPU memory.
- GPU memory bandwidth: HBM memory is secure against physical attacks and remains unencrypted.
However, the following aspects are impacted by encryption and decryption overhead:
- CPU-GPU interconnect bandwidth: Limited by CPU encryption performance, currently around 4 GBytes/sec.
- Data transfer throughput across non-secure interconnects: Increased latency due to encrypted bounce buffers in unprotected memory used for staging confidential data.
💡 Note
For a deeper dive into NVIDIA’s work in this space, check out their detailed blog: Confidential Computing on NVIDIA H100 GPUs for Secure and Trustworthy AI.
Azure Confidential AI Options
At the time of writing this post, there are not a lot of options for running Confidential AI workloads on Azure, but that’s not necessarily a bad thing. The choices essentially fall into two big categories:
- PaaS
- Azure OpenAI Service (Whisper model): Currently in preview, used for confidential speech-to-text transcription.
- Azure Container Instances: Supports Confidential Containers for CPU-only inferencing and training, running on AMD SEV-SNP powered VM SKUs behind the scenes.
- IaaS
- Confidential VMs: Available in a variety of SKUs, which use either AMD SEV-SNP or Intel TDX. Similar use case to ACI as they’re suitable for CPU-based AI workloads—like data pre-processing, or training and inferencing for smaller models—while protecting sensitive code and data in use.
- Confidential VMs with Confidential GPUs: Available via the NCCads_H100_v5 VM series.
- AMD SEV-SNP and NVIDIA A100, not H100, GPUs were previously available in limited preview, but it appears that option is no longer available!
While training and inference are the main AI workloads leveraging GPUs, other parts of the AI lifecycle (like data preprocessing or hyperparameter tuning) can also benefit from GPU acceleration. It really depends on your use case—so it’s worth testing to see if the performance gains justify the cost.
FYI: ACI
Azure Container Instances (ACI) makes confidential inference workloads easier to deploy, with flexible resource allocation and pay-as-you-go pricing. There’s no infrastructure management required, aside from provisioning the ACI resource itself. Behind the scenes, your containerized workloads run seamlessly on an AMD SEV-SNP-powered Confidential VM.
You can check out some sample deployments of confidential inference using confidential containers on ACI.
NVIDIA H100 powered VM SKUs
Now, let’s talk about the NCCads H100 v5 series. It’s a powerhouse. Here’s how the Azure docs describes it:
📖 Quote:
“The NCCads H100 v5 series is powered by 4th-generation AMD EPYC™ Genoa processors and NVIDIA H100 Tensor Core GPU. These VMs feature 1 NVIDIA H100 NVL GPU with 94 GB memory (VRAM), 40 non-multithreaded AMD EPYC Genoa processor cores, and 320 GiB of system memory.”
Currently, there’s only one available SKU in this series… And you can probably already guess the specs:
Standard_NCC40ads_H100_v5- 40 vCPUs (non-multithreaded)
- 320 GiB RAM
- 1x NVIDIA H100 NVL GPU (94 GB VRAM)
This is the only VM SKUs to extend the Trusted Execution Environment (TEE) to the attached GPU.
💡 Note
At the time of writing, I haven’t spotted any VM SKUs that use Intel TDX with the H100.
Pricing
As you might expect, a 40-core CPU & GPU VM combination comes with a price tag. Here’s the monthly cost for a Linux instance:
- East US 2: EUR 4,769.60 (~ USD 5,161.97)
- West Europe: EUR 6,081.58 (~ USD 6,577.82)
For cost optimization, 1-year and 3-year reserved instances are available. Based on the Azure Pricing API, these SKUs should also support Spot VMs and low-priority VMs in Azure Batch, with significantly lower pricing:
- East US 2 (Low Prio VM): USD 1.396/hour
- West Europe (Low Prio VM): USD 4.296/hour
However, when I tried creating an Azure Batch pool in East US 2, I got the message:
“Confidential VM is not supported in the current Batch account’s region.”
So it looks like the availability for these services might still be limited.
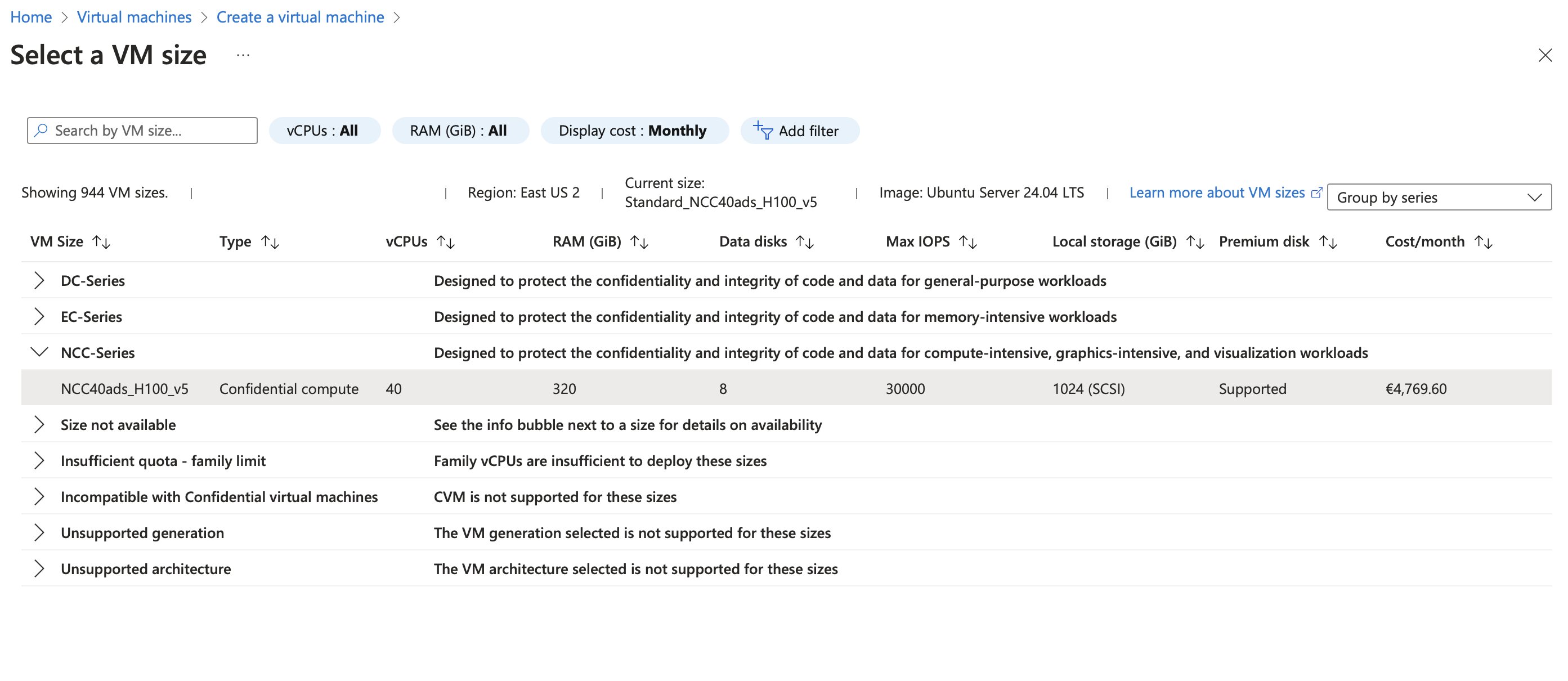
Availability
The Azure Pricing API suggests this SKU is also available in South Central US and Central US, but when I checked the Azure Portal, it showed as unavailable in those regions. It’s likely rolling out gradually.
If you want to check pricing and availability for yourself, you can query the Azure Pricing API using the following URL:
https://prices.azure.com/api/retail/prices?api-version=2023-01-01-preview&meterRegion='primary'&$filter=armSkuName eq 'Standard_NCC40ads_H100_v5'
Demo Time: Running Confidential AI Workloads
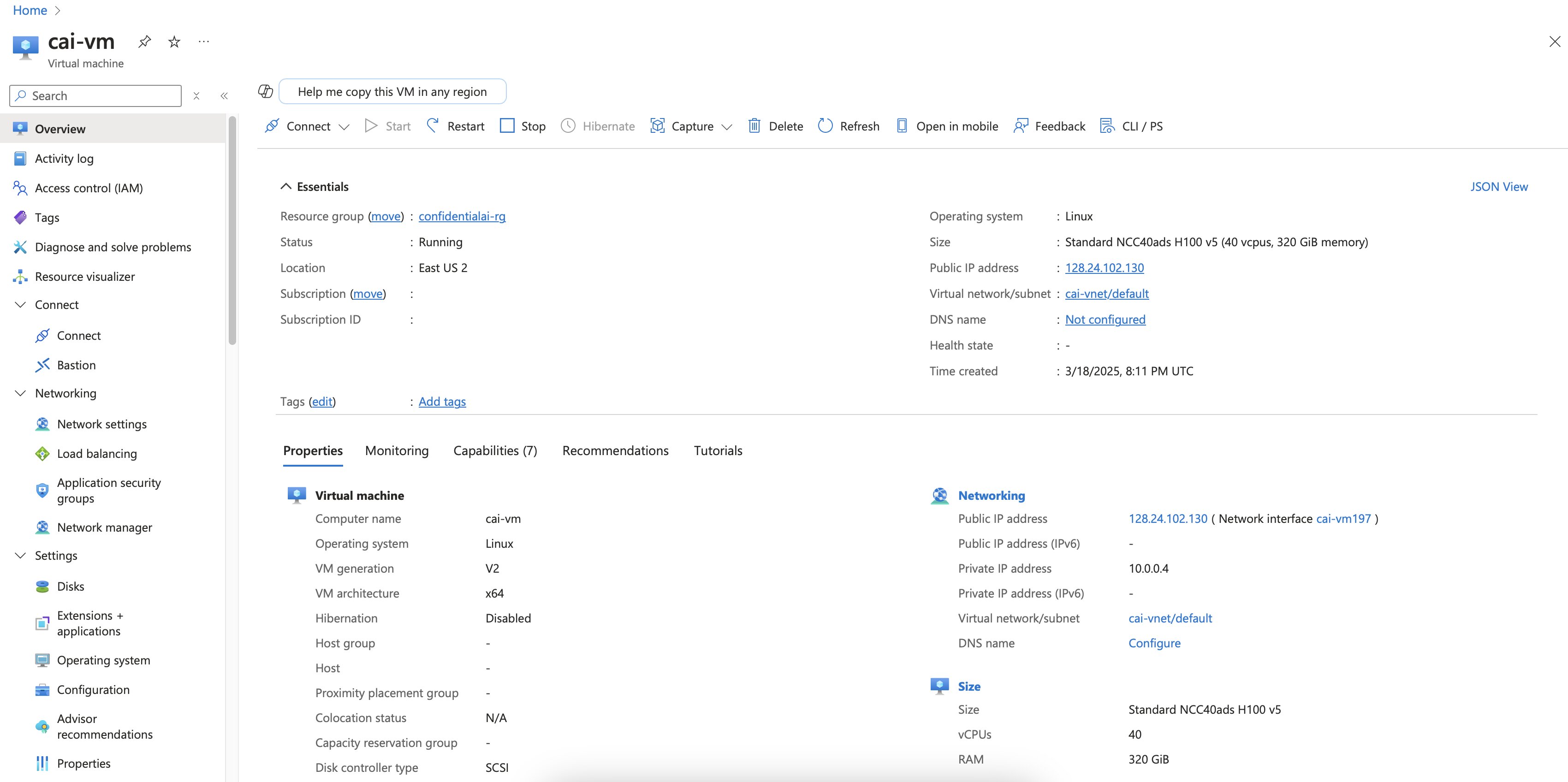
Let’s see how far I can get with running my own AI workload on a Confidential VM. Provisioning the VM is straightforward and follows the usual process for Confidential VMs on Azure. I’m using a Bicep template I’ve had for a while, which deploys a Confidential VM. By default, this setup uses Platform-Managed Keys (PMK), but you can opt for Customer-Managed Keys (CMK) if needed.
My plan is to run a containerized AI inference server that will use the CGPU, rather than installing everything manually. We’ll still need to install some bits and pieces before we can properly pass the GPU through to the containerized process. Let’s begin!
Bicep Deployment
Here’s the Bicep template I used to deploy this Confidential GPU-enabled CVM:
targetScope = 'resourceGroup'
@description('Required. Specifies the Azure location where the key vault should be created.')
param location string = resourceGroup().location
@description('Required. Admin username of the Virtual Machine.')
param adminUsername string
@description('Required. Password or ssh key for the Virtual Machine.')
@secure()
param adminPasswordOrKey string
@description('Optional. Type of authentication to use on the Virtual Machine.')
@allowed([
'password'
'sshPublicKey'
])
param authenticationType string = 'password'
@description('Required. Name of the Virtual Machine.')
param vmName string
@description('Optional. Size of the VM.')
@allowed([
'Standard_NCC40ads_H100_v5'
])
param vmSize string = 'Standard_NCC40ads_H100_v5'
@description('Optional. OS Image for the Virtual Machine')
@allowed([
'Ubuntu 24.04 LTS Gen 2'
])
param osImageName string = 'Ubuntu 24.04 LTS Gen 2'
@description('Optional. OS disk type of the Virtual Machine.')
@allowed([
'Premium_LRS'
'Standard_LRS'
'StandardSSD_LRS'
])
param osDiskType string = 'Premium_LRS'
@description('Optional. Enable boot diagnostics setting of the Virtual Machine.')
@allowed([
true
false
])
param bootDiagnostics bool = false
@description('Optional. Specifies the EncryptionType of the managed disk. It is set to DiskWithVMGuestState for encryption of the managed disk along with VMGuestState blob, and VMGuestStateOnly for encryption of just the VMGuestState blob. NOTE: It can be set for only Confidential VMs.')
@allowed([
'VMGuestStateOnly' // virtual machine guest state (VMGS) disk
'DiskWithVMGuestState' // Full disk encryption
])
param securityType string = 'DiskWithVMGuestState'
var imageList = {
'Ubuntu 24.04 LTS Gen 2': {
publisher: 'canonical'
offer: 'ubuntu-24_04-lts' // 👈 Specific confidential VM image offer!
sku: 'cvm' // 👈 Specific confidential VM image SKU!
version: 'latest'
}
}
var virtualNetworkName = '${vmName}-vnet'
var subnetName = '${vmName}-vnet-sn'
var subnetResourceId = resourceId('Microsoft.Network/virtualNetworks/subnets', virtualNetworkName, subnetName)
var addressPrefix = '10.0.0.0/16'
var subnetPrefix = '10.0.0.0/24'
var isWindows = contains(osImageName, 'Windows')
resource publicIPAddress 'Microsoft.Network/publicIPAddresses@2023-06-01' = {
name: '${vmName}-ip'
location: location
sku: {
name: 'Basic'
}
properties: {
publicIPAllocationMethod: 'Dynamic'
}
}
resource networkSecurityGroup 'Microsoft.Network/networkSecurityGroups@2023-06-01' = {
name: '${vmName}-nsg'
location: location
properties: {
securityRules: [
{
name: (isWindows ? 'RDP' : 'SSH')
properties: {
priority: 100
protocol: 'Tcp'
access: 'Allow'
direction: 'Inbound'
sourceAddressPrefix: '*'
sourcePortRange: '*'
destinationAddressPrefix: '*'
destinationPortRange: (isWindows ? '3389' : '22')
}
}
]
}
}
resource virtualNetwork 'Microsoft.Network/virtualNetworks@2023-06-01' = {
name: virtualNetworkName
location: location
properties: {
addressSpace: {
addressPrefixes: [
addressPrefix
]
}
subnets: [
{
name: subnetName
properties: {
addressPrefix: subnetPrefix
networkSecurityGroup: {
id: networkSecurityGroup.id
}
}
}
]
}
}
resource networkInterface 'Microsoft.Network/networkInterfaces@2023-06-01' = {
name: '${vmName}-nic'
location: location
properties: {
ipConfigurations: [
{
name: 'ipconfig1'
properties: {
privateIPAllocationMethod: 'Dynamic'
subnet: {
id: subnetResourceId
}
publicIPAddress: {
id: publicIPAddress.id
}
}
}
]
}
dependsOn: [
virtualNetwork
]
}
resource confidentialVm 'Microsoft.Compute/virtualMachines@2023-09-01' = {
name: vmName
location: location
identity: {
type: 'SystemAssigned'
}
properties: {
diagnosticsProfile: {
bootDiagnostics: {
enabled: bootDiagnostics
}
}
hardwareProfile: {
vmSize: vmSize
}
storageProfile: {
osDisk: {
createOption: 'FromImage'
managedDisk: {
storageAccountType: osDiskType
securityProfile: {
securityEncryptionType: securityType
}
}
}
imageReference: imageList[osImageName]
}
networkProfile: {
networkInterfaces: [
{
id: networkInterface.id
}
]
}
osProfile: {
computerName: vmName
adminUsername: adminUsername
adminPassword: adminPasswordOrKey
linuxConfiguration: ((authenticationType == 'password') ? null : {
disablePasswordAuthentication: 'true'
ssh: {
publicKeys: [
{
keyData: adminPasswordOrKey
path: '/home/${adminUsername}/.ssh/authorized_keys'
}
]
}
})
windowsConfiguration: (!isWindows ? null : {
enableAutomaticUpdates: 'true'
provisionVmAgent: 'true'
})
}
securityProfile: {
uefiSettings: {
secureBootEnabled: true
vTpmEnabled: true
}
securityType: 'ConfidentialVM'
}
}
}
Nothing fancy, just a VM that’s deployed and ready to roll.
While I could configure the AI inferencing engine separately, running it inside a container seems more representative of real-world workloads. I won’t deploy Kubernetes just yet, as I am focused on understanding what’s required to run confidential inference efficiently.
After a bit of searching, I figured we’d need these items to get started:
- NVIDIA Drivers
- Podman
- NVIDIA Container Toolkit
- Container Device Interface (CDI)
Microsoft has a guide for setting up NVIDIA drivers on Azure’s N-series VMs (docs). Since the NCC-series belongs to the N-series, I expected it to work without a problem.
I started with the recommended installation commands:
sudo apt update
sudo apt install -y ubuntu-drivers-common
sudo ubuntu-drivers install
sudo reboot now
Unfortunately, I encountered errors when running ubuntu-drivers install. To debug this, I ran:
ubuntu-drivers devices
This listed the available drivers:
devadm hwdb is deprecated. Use systemd-hwdb instead.
ERROR:root:aplay command not found
== /sys/devices/... ==
vendor : NVIDIA Corporation
model : GH100 [H100L 94GB]
driver : nvidia-driver-570 - third-party non-free recommended
driver : nvidia-driver-565 - third-party non-free
driver : nvidia-driver-560 - third-party non-free
driver : nvidia-driver-535 - distro non-free
...
The ERROR:root:aplay message is pretty harmless, since most VMs don’t need sound output.
I figured I’d install the nvidia-driver-570. When in doubt you should always install the highest number, right?
sudo apt install -y nvidia-driver-570
This was a mistake, as I ended up with multiple versions installed. On the bright side, nvidia-smi (NVIDIA System Management Interface) was installed, but it wasn’t working properly:
nvidia-smi
# Failed to initialize NVML: Driver/Library version mismatch
This error was self-explanatory—somewhere along the way, I made a mistake with the installation. At least it wasn’t a generic “Error: exception occurred.”
Azure/az-cgpu-onboarding
I was a little stuck at this point, but then I came across a helpful GitHub repository hosted by Microsoft called Azure/az-cgpu-onboarding. It’s designed to help Azure customers get started with Confidential GPUs, offering documentation, Bash and PowerShell onboarding scripts, and demos for deploying solutions using platform-managed or customer-managed keys.
The repository also includes code from the NVIDIA/nvtrust repo and shows how to perform GPU attestation in Python. I found this very useful, as Python is more accessible to most people. The scripts are straightforward, and you can easily follow them with a little patience.
This repository is a great example of how to quickly get something valuable up and running for customers. I didn’t notice any shortcuts in the scripts, which is reassuring.
From the repo, I learned a few things:
- Minimum kernel version for CGPUs: The required version is 6.5.0-1024-azure, so be cautious when using distributions with different kernel versions.
- Required driver packages:
nvidia-driver-550-server-openlinux-modules-nvidia-550-server-open-azure
Resolving the Driver Issue
Best of all, the repository included information about the error I was encountering! To be cautious, I redeployed the VM, but this time, instead of installing ubuntu-drivers-common, I deviated from the “N-series driver setup” docs and installed driver version 570 instead of 550. Notice that I have to install two packages: nvidia-driver-570-server-open and linux-modules-nvidia-570-server-open-azure; not nvidia-driver-570.
sudo apt update
sudo apt install -y gcc g++ make
sudo apt install -y nvidia-driver-570-server-open linux-modules-nvidia-570-server-open-azure
The onboarding script also sets up persistent mode, which ensures that the GPU is ready when the Linux system boots. This is not necessary for Windows machines, but it’s useful for Linux setups.
# Enable persistence mode and set GPU ready state on boot
sudo nvidia-smi -pm 1
echo "add nvidia persitenced on reboot."
sudo bash -c 'echo "#!/bin/bash" > /etc/rc.local; echo "nvidia-smi -pm 1" >>/etc/rc.local; echo "nvidia-smi conf-compute -srs 1" >> /etc/rc.local;'
sudo chmod +x /etc/rc.local
After running this, I had no more errors, and the correct driver version showed up:
nvidia-smi --query-gpu=driver_version --format=csv,noheader
# 570.86.15
Finally, nvidia-smi worked, and I could see the H100 GPU. It’s tempting to turn this into the world’s most expensive remote Steam box, but with the VM costing EUR 6.59 per hour, there’s no time for messing around.
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.86.15 Driver Version: 570.86.15 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA H100 NVL On | 00000001:00:00.0 Off | 0 |
| N/A 34C P0 63W / 400W | 1MiB / 95830MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
Confidential Compute Status
To check the confidential compute status and environment, you can use the following commands. This gives a quick indication if everything is working, but keep in mind that these commands don’t provide cryptographic attestation (which ensures the system is in the expected state).
nvidia-smi conf-compute -f
# CC status: ON
nvidia-smi conf-compute -e
# CC Environment: PRODUCTION
In case you’re wondering, there are three confidential computing modes for the NVIDIA H100:
- CC-Off: Standard operation, with no confidential computing features enabled.
- CC-On: Fully activates all confidential computing features, including firewalls and disabled performance counters to prevent side-channel attacks.
- CC-DevTools: A partial CC mode for developers, where security protections are disabled, and performance counters are enabled to allow profiling and tracing with tools like NSys Trace.
Optional: Installing CUDA Toolkit
Although I didn’t strictly need to install the CUDA toolkit (since the container images I plan to use already include the necessary tools), I decided to install it anyway for convenience.
# This is optional since we will use
# container images that get shipped with the CUDA toolkit
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo apt install -y ./cuda-keyring_1.1-1_all.deb
sudo apt update
sudo apt -y install cuda-toolkit-12-8
Installing Podman
Next, I installed Podman for container management:
sudo apt install -y podman
I also installed the NVIDIA Container Toolkit to enable GPU-accelerated containers:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
Generating a CDI Specification
The NVIDIA Container Toolkit includes the nvidia-ctk tool, which is essential for generating the Container Device Interface (CDI) specification file that allows Podman to detect GPUs:
sudo nvidia-ctk cdi generate --output=/etc/cdi/nvidia.yaml
Verifying GPU Access from Containers
Finally, I ran a container that has the CUDA toolkit pre-installed to verify that it could access the GPU:
podman run --rm --device nvidia.com/gpu=all docker.io/nvidia/cuda:12.8.0-base-ubuntu24.04 nvidia-smi
# Trying to pull docker.io/nvidia/cuda:12.8.0-base-ubuntu24.04...
#
# Getting image source signatures
# Copying blob 4b650590013c done |
# Copying blob de44b265507a done |
# Copying blob 5f5407c3a203 done |
# Copying blob 7c19210cd82d done |
# Copying blob 0f8429c62360 done |
# Copying config e1410ea223 done |
# Writing manifest to image destination
#
# Tue Mar 18 22:21:26 2025
# +-----------------------------------------------------------------------------------------+
# | NVIDIA-SMI 570.86.15 Driver Version: 570.86.15 CUDA Version: 12.8 |
# |-----------------------------------------+------------------------+----------------------+
# | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
# | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
# | | | MIG M. |
# |=========================================+========================+======================|
# | 0 NVIDIA H100 NVL On | 00000001:00:00.0 Off | 0 |
# | N/A 34C P0 63W / 400W | 1MiB / 95830MiB | 0% Default |
# | | | N/A |
# +-----------------------------------------+------------------------+----------------------+
#
# +-----------------------------------------------------------------------------------------+
# | Processes: |
# | GPU GI CI PID Type Process name GPU Memory |
# | ID ID Usage |
# |=========================================================================================|
# | No running processes found |
# +-----------------------------------------------------------------------------------------+
At this point, everything seems to be working correctly. I’m ready to move forward with my AI workloads!
Running a workload
For this demo, I’ll be downloading a language model directly from Huggingface and storing it on the VM’s disk. Then, I’ll mount it as a volume inside my container.
Before doing that though I’ll first need to install git-lfs. Git Large File Storage (LFS) handles large files like datasets, audio, and videos by replacing them with text pointers in Git and storing the actual content remotely.
sudo apt install git-lfs
I’ve selected the SmolLM2-1.7B-Instruct model, which may seem a little unusual because it’s designed for smaller devices that don’t have 94 GB of VRAM. However, feel free to swap it for any other model, like Phi4 or something significantly larger, if you prefer.
mkdir -p ~/models
cd ~/models
git clone https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct
cd SmolLM2-1.7B-Instruct
llama.cpp
Next, we’ll use the llama.cpp inferencing engine to run the model. The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide range of hardware, locally and in the cloud.
However, llama.cpp doesn’t accept the safetensors files that come with the model, so we need to convert them to a different format: GGUF. Luckily, the llama.cpp maintainers offer a container image that includes all the necessary tools, including a conversion script. Fortunately, we can just convert it with a simple command.
cd ~
podman run --device nvidia.com/gpu=all \
--volume ~/models:/models \
ghcr.io/ggml-org/llama.cpp:full-cuda \
--convert "/models/SmolLM2-1.7B-Instruct" \
--outfile "/models/SmolLM2-1.7B-Instruct/model.gguf"
# INFO:hf-to-gguf:Set model quantization version
# INFO:gguf.gguf_writer:Writing the following files:
# INFO:gguf.gguf_writer:/models/SmolLM2-1.7B-Instruct/model.gguf: n_tensors = 218, total_size = 3.4G
# Writing: 100%|██████████| 3.42G/3.42G [00:07<00:00, 484Mbyte/s]
# INFO:hf-to-gguf:Model successfully exported to /models/SmolLM2-1.7B-Instruct/model.gguf
🤔 Food for thought
The conversion process might have been faster if I had used that speedy temporary storage, but if you want to ensure that everything stays confidential, then enabling confidential temp disk encryption requires some extra steps. If you want to explore that, check out my detailed blog post here.
Now, we’re almost there! Let’s run a prompt against the model.
cd ~
podman run --device nvidia.com/gpu=all \
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--volume ~/models:/models \
ghcr.io/ggml-org/llama.cpp:full-cuda --run \
--model /models/SmolLM2-1.7B-Instruct/model.gguf \
--prompt "Building a website can be done in 10 simple steps:" \
--predict 2048 \
--n-gpu-layers 999
That’s a lot of flags! The ones before the container image name “ghcr.io/ggml-org/llama.cpp:full-cuda” belong to podman, while those after it are used to configure llama.cpp.
--model: path to the model.--prompt: the prompt that starts the generation.--predict: number of tokens to predict (default: -1, which means infinity).--n-gpu-layers N: number of layers to store in VRAM.- I have set this to something absurdly high.
Here’s the output the model generated:
...
system
You are a helpful AI assistant named SmolLM, trained by Hugging Face
user
Building a website can be done in 10 simple steps:
assistant
1. Choose a domain name: This is the address that users will use to access your website. Make sure it's easy to remember and available.
2. Register your domain: Once you have your domain name, you need to register it. You can do this through a domain registrar like GoDaddy.
3. Select a web host: Your web host will provide the necessary infrastructure for your website to exist. Look for one that meets your needs in terms of storage, bandwidth, and customer support.
4. Plan your website: Create a content plan, decide on the design of your website, and choose the necessary tools for it.
5. Build your website: Start building your website using your chosen tools. You can choose to use a content management system (CMS) like WordPress or a website builder like Wix.
...
Not only did we get a nice set of instructions on how to set up a website, but we also successfully used the confidential GPU. From a user’s perspective, this process feels almost transparent and works just like any other Linux setup. (This is fantastic because it allows us to leverage all the skills we’ve developed over the years.)
Every 1.0s: nvidia-smi
Tue Mar 18 22:48:09 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.86.15 Driver Version: 570.86.15 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA H100 NVL On | 00000001:00:00.0 Off | 0 |
| N/A 45C P0 295W / 400W | 5168MiB / 95830MiB | 81% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 10079 C ./llama-cli 5010MiB |
+-----------------------------------------------------------------------------------------+
vLLM
vLLM is a fast and easy-to-use library for language model inference and serving. It was originally developed in the Sky Computing Lab at UC Berkeley and has evolved into a community-driven project with contributions from both academia and industry.
The vllm serve command has a whole bunch of engine arguments, so it’s a good idea to keep that list handy. You can run vLLM in a container, and that’s exactly what we’ll do here.. Running the container causes the vllm serve command to get invoked.
podman run --device nvidia.com/gpu=0 \
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--volume ~/models:/mnt/models \
--publish 8000:8000 \
--env "TRANSFORMERS_OFFLINE=1" \
--env "HF_DATASET_OFFLINE=1" \
vllm/vllm-openai:latest \
--model "/mnt/models/SmolLM2-1.7B-Instruct" \
--dtype auto \
--api-key token-abc123
vLLM supports loading safetensor files, so there’s no need to convert them to GGUF like we did before.
💡 Fun fact
If you’re using the VS Code Remote SSH extension to connect to the CVM, you’ll notice that once the container image is running, it automatically tries to forward the remote port to your local machine.
This way, you could even run the Python script locally while it communicates across the SSH-tunnel.
It also includes an OpenAI-compatible endpoint, so let’s follow this guide in the vLLM docs to get it up and running. I had to do a bit of tweaking to get vLLM to load the model from HuggingFace, but once it was up, everything worked as expected.
Next, I’ll set up a new venv and use pip to install the OpenAI Python library.
python3 -m venv ./dev
./dev/bin/python3 -m pip install openai
Then, using this simple code snippet, we can hit the endpoint.
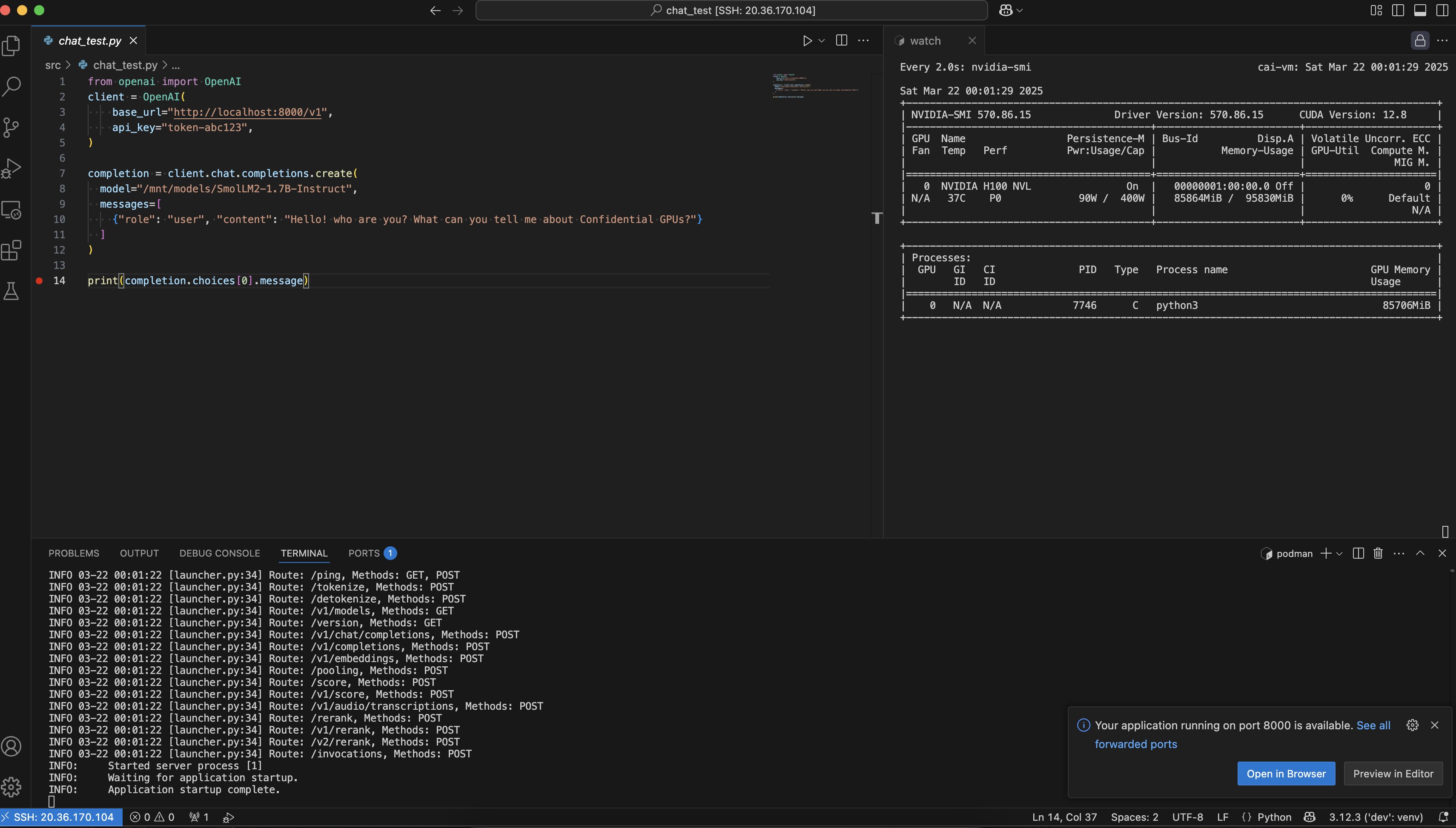
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-abc123",
)
completion = client.chat.completions.create(
model="/mnt/models/SmolLM2-1.7B-Instruct",
messages=[
{"role": "user", "content": "Hello! Who are you? What can you tell me about Confidential GPUs?"}
]
)
print(completion.choices[0].message)
Sure enough, the output is:
./dev/bin/python3 src/chat_test.py
# ChatCompletionMessage(content="Hi! I'm SmolLM, but if you'd like, you can also
# call me Genet, which is short for Intelligent Generative AI. I'm an AI language
# model designed to assist with language tasks. I don't have personal experiences
# or individual memories, but I can share
# information and provide helpful responses. Now, regarding your question about
# Confidential GPUs, I might not have detailed information or specifics about these
# specific GPUs, but I can certainly tell you what 'GPUs' generally stand for and what
# they are used for.\n\nGPUs, or Graphics Processing Units, are specialized computer chips
# that process large amounts of data at high speeds. They are used in high-performance computing
# such as gaming, scientific simulations, data analysis, and machine learning tasks.\n\nHowever,
# there are many different types of GPUs (like NVIDIA GeForce or AMD Radeon), so it's tough
# to provide specifics on 'Confidential GPUs'. Let me know if you want to learn more about
# how GPUs work or their different applications!",
# refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[],
# reasoning_content=None)
When I run nvidia-smi, you can see that the python3 process is actively utilizing the GPU. This process is related to vLLM, not to my test chat client.
Wed Mar 19 22:29:00 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.86.15 Driver Version: 570.86.15 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA H100 NVL On | 00000001:00:00.0 Off | 0 |
| N/A 37C P0 91W / 400W | 85864MiB / 95830MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 13833 C python3 85706MiB |
+-----------------------------------------------------------------------------------------+
Attestation
Confidential computing relies on one critical element: attestation. Before starting any workload, you must verify that the TEE, the CVM, and the CGPU are running in the intended state.
💡 Note
You may often see this attestation in action as a pre-requisite to performing Secure Key Release, which something I’ve also written about (part 1/2). This process releases a private key from a key management system (like Azure Key Vault Premium or Managed-HSM) to decrypt a symmetric key—often 256-bit AES—that was encrypted with the corresponding public key. A symmetric key be used to quickly encrypt or decrypt blocks of data securely within the TEE.
GPU attestation
Attestation ensures that the machine is in its expected state. But when should you trigger it? Anytime you like! The maintainers of Azure/az-cgpu-onboarding included a couple of examples, based on the NVIDIA/nvtrust project, on how to run the CGPU attestation process:
- local_gpu_verifier: A Python example
- local_gpu_verified_http_service: A Go wrapper around the Python script
The verifier is a Python-based tool that checks GPU measurements by comparing runtime values with trusted golden measurements. It’s designed to verify whether the software and hardware state of the GPU matches the intended configuration. The tool supports both single-GPU and multi-GPU systems.
sudo ./dev/bin/python3 -m verifier.cc_admin
Generating random nonce in the local GPU Verifier ..
Number of GPUs available : 1
Fetching GPU 0 information from GPU driver.
All GPU Evidences fetched successfully
-----------------------------------
Verifying GPU: GPU-7ad86712-c7c1-e8af-08ca-bf2112d275d5
Driver version fetched : 570.86.15
VBIOS version fetched : 96.00.9f.00.04
Validating GPU certificate chains.
The firmware ID in the device certificate chain matches the one in the attestation report.
GPU attestation report certificate chain validation successful.
The certificate chain revocation status verification successful.
Authenticating attestation report
The nonce in the SPDM GET MEASUREMENT request matches the generated nonce.
Driver version fetched from the attestation report : 570.86.15
VBIOS version fetched from the attestation report : 96.00.9f.00.04
Attestation report signature verification successful.
Attestation report verification successful.
Authenticating the RIMs.
Authenticating Driver RIM
Fetching the driver RIM from the RIM service.
RIM Schema validation passed.
Driver RIM certificate chain verification successful.
Certificate chain revocation status verification successful.
Driver RIM signature verification successful.
Driver RIM verification successful
Authenticating VBIOS RIM.
Fetching the VBIOS RIM from the RIM service.
RIM Schema validation passed.
VBIOS RIM certificate chain verification successful.
Certificate chain revocation status verification successful.
VBIOS RIM signature verification successful.
VBIOS RIM verification successful
Comparing measurements (runtime vs golden)
Runtime measurements match the golden measurements.
GPU is in expected state.
GPU 0 with UUID GPU-7ad86712-c7c1-e8af-08ca-bf2112d275d5 verified successfully.
GPU Ready State is already READY
GPU Attestation is Successful.
The cc_admin module retrieves GPU details, the attestation report, and the driver RIM associated with the GPU version. It then authenticates the RIMs and verifies the attestation report. The verifier compares runtime measurements with the golden measurements stored in the RIM.
The result from cc_admin is a base64url-encoded string, which can be easily decoded. This value is a signed JSON Web Token (JWT) consisting of:
- A JSON Object Signing and Encryption (JOSE) header
- A JSON Web Signature (JWS) payload (claims)
- A JWS signature
To decode, simply split the string by the . (dot) and base64url-decode each segment.
💡 base64url is a slightly modified version of base64, designed to be URL and filename-safe.
Here’s the decoded result from the Entity Attestation Token labeled JWT:
// Header
{
"alg": "HS256",
"typ": "JWT"
}
// Payload
{
"sub": "NVIDIA-PLATFORM-ATTESTATION",
"nbf": 1742420436,
"exp": 1742424156,
"iat": 1742420556,
"jti": "1d031b5b-701a-48f0-a1d0-ffa2d0a89cce",
"x-nvidia-ver": "2.0",
"iss": "LOCAL_GPU_VERIFIER",
"x-nvidia-overall-att-result": true,
"submods": {
"GPU-0": [
"DIGEST",
[
"SHA256",
"2137f0d434edad501c8339ab562cf3d59c0fe40bd5baab34902ad8fd151184fb"
]
]
},
"eat_nonce": "7897515adf25b0cc334c04a9199254b70ecc85111aab794326e3876a831ad7d0"
}
The GPU-0 object value decodes to:
// Header
{
"alg": "HS256",
"typ": "JWT"
}
// Payload
{
"measres": "success",
"x-nvidia-gpu-arch-check": true,
"x-nvidia-gpu-driver-version": "570.86.15",
"x-nvidia-gpu-vbios-version": "96.00.9F.00.04",
"x-nvidia-gpu-attestation-report-cert-chain-validated": true,
"x-nvidia-gpu-attestation-report-parsed": true,
"x-nvidia-gpu-attestation-report-nonce-match": true,
"x-nvidia-gpu-attestation-report-signature-verified": true,
"x-nvidia-gpu-driver-rim-fetched": true,
"x-nvidia-gpu-driver-rim-schema-validated": true,
"x-nvidia-gpu-driver-rim-cert-validated": true,
"x-nvidia-gpu-driver-rim-signature-verified": true,
"x-nvidia-gpu-driver-rim-measurements-available": true,
"x-nvidia-gpu-vbios-rim-fetched": true,
"x-nvidia-gpu-vbios-rim-schema-validated": true,
"x-nvidia-gpu-vbios-rim-cert-validated": true,
"x-nvidia-gpu-vbios-rim-signature-verified": true,
"x-nvidia-gpu-vbios-rim-measurements-available": true,
"x-nvidia-gpu-vbios-index-no-conflict": true,
"secboot": true,
"dbgstat": "disabled",
"eat_nonce": "7897515adf25b0cc334c04a9199254b70ecc85111aab794326e3876a831ad7d0",
"hwmodel": "GH100 A01 GSP BROM",
"ueid": "537812451488355309938117147972025974723560610032",
"oemid": "5703",
"iss": "LOCAL_GPU_VERIFIER",
"nbf": 1742420436,
"exp": 1742424156,
"iat": 1742420556,
"jti": "d117b269-dab6-4ae8-b54d-7cd8aac133b1"
}
To make sense of these values, keep this list of Claim definitions handy.
CVM Guest Attestation
Along with CGPU attestation, CVM guest attestation backed by AMD SEV-SNP plays a crucial role, as it enables running the entire OS inside a TEE.
Performing guest attestation verifies that your confidential VM is secured by a trusted hardware-backed TEE, ensuring it provides confidentiality guarantees correctly. For implementation details, check out the Azure/confidential-computing-cvm-guest-attestation repository.
I won’t dive too deep into guest attestation here since I’ve already covered it extensively in my Secure Key Release blogs. I highly recommend checking that out instead!
Retro
I highly recommend checking out (Dr.) Mark Russinovich’s blog, Azure AI Confidential Inferencing: Technical Deep-Dive, for an even closer look. It even touches on something that truly completes the circle—end-to-end confidentiality. That means sending an HTTP request from your browser to a service running inside a TEE and getting a response back, all while ensuring data remains protected throughout the entire process.
It’s a fascinating read that really ties together everything I’ve covered about confidential computing. The pieces are falling into place to enable truly confidential AI, and it’s exciting to see this vision become reality. Huge respect to the brilliant minds pushing this technology forward—hats off to those making confidential AI possible!
Related posts
- Making Sense of AI
- Exploring AI CPU-Inferencing with Azure Cobalt 100
- Windows Containers: Azure Pipeline Agents with Entra Workload ID in Azure Kubernetes Service
- Register Azure Pipeline Agents using Entra Workload ID on Azure Kubernetes Service
- Azure Confidential Computing: CoCo - Confidential Containers
- Azure Confidential Computing: Confidential Temp Disk Encryption
- Azure Confidential Computing: Secure Key Release - Part 2
- Azure Confidential Computing: Microsoft Azure Attestation
- Azure Confidential Computing: Azure RBAC for Secure Key Release
- Azure Confidential Computing: Verifying Microsoft Azure Attestation JWT tokens
- Azure Confidential Computing: Secure Key Release
- Azure Confidential Computing: Confidential VMs
- Azure Confidential Computing: IaaS
- Azure Confidential Computing
- Key Vault for Azure virtual machines extension