Open Policy Agent
In this post
I am getting increasingly more questions about how to tackle certain “enterprise cloud governance” issues. At the risk of sounding slightly anecdotal, I’m going to assume that a lot more enterprises are taking advantage of those capabilities. Many of these enterprises need assurances that there is as little deviation from the rules as possible. In many instances, they have to comply with industry-specific standards and other times they want to have guard rails up, to mitigate human mistakes.
There are many such “policy decision issues” across the cloud-native ecosystem that we might encounter. Here are a few, perhaps even very obvious, examples of policy decisions that you might have run into yourself:
- When a microservice wants to call into another microservice, there might be a policy decision that needs to determine whether or not the call is allowed.
- Is the request authenticated?
- Is this customer eligible for a discount?
- When deploying an Azure Resource Manager template via a CI/CD pipeline are we sure that whoever is triggering the deployment, is authorized to perform the deployment and are potential other conditions met as well? Such other conditions can also be just about anything your organisation deems important:
- Does this evening have a planned change window?
- Has the application shut down properly? (A whole discussion can be had on the semantics of this alone.)
These different software applications can all have their unique way of implementing, extending and handling policy and authorization. Depending on the software, it might come with its own paradigm, perhaps even a new syntax, that you will need to learn and maintain. That is where a possible problem might arise when I stop to think about it. As the complexity of your production environment grows, so does the difficulty of managing consistency, risk and error.
Through the adoption of Infrastructure-as-Code, we now have ways to codify many of our best practices surrounding our infrastructure. What if we could apply those same principles, along with some DevOps practices, to deliver security policies via policies-as-code?
What is Open Policy Agent?
Open Policy Agent (OPA) is a platform-agnostic and open source policy engine that gives you a unified toolset and way to unify policy enforcement. It was designed explicitly for writing and validating policies.
OPA delivers one language, one toolset, and allows for many integrations to provide unified policy control across the cloud-native stack. The software itself is written in Golang and its source is available on GitHub, it is licensed under the Apache License 2.0.
OPA is a full-featured policy engine that offloads policy decisions from your software. You can think of it as a concierge for your software who can answer detailed questions on behalf of your users to meet their specific needs. OPA provides the building blocks for enabling better control and visibility over policy in your systems.
OPA has recently graduated from the Cloud Native Computing Foundation, meaning it has been picked up and battle-tested by an impressive list of adopters (Bol.com, Netflix, Cloudflare, etc..). Completing the graduation process is a pretty significant feat, as it implies that the project has passed several audits, security assessments and has a stable governance process, amongst many other things. Along with the project’s creators, Styra, current maintainers include: Google, VMware, Microsoft and many others.
I stumbled upon OPA via the Gatekeeper project, which uses OPA, when talking about Azure Governance at Cloudbrew 2019. Azure Policy can integrate with Gatekeeper to apply enforcements and safeguards on Kubernetes clusters in a centralized, consistent manner. Additionally, Azure Policy then makes it possible to manage and report on the compliance state of your Kubernetes clusters from within the Azure Portal.
Azure DevOps has built-in OPA support, as well, via one of its “approvals and checks” in Azure Pipelines environments! The Artifact Policy check can be used to determine whether or not certain stages of a pipeline can be executed, based off of a custom policy evaluation.
Policies
Conceptually, OPA’s policies can be compared to “if-then” statements which mirror real-world policies often found in PDFs and Sharepoint wikis. Those policies can be written using a declarative approach, essentially enabling you to write policy-as-code via OPA’s domain-specific language called “Rego”.
All kinds of software, from web services to even Linux pluggable authentication modules, can offload policy decisions (queries) to OPA by executing queries against it. OPA evaluates policies and their associated data to produce policy decisions, which are sent back to the requester.
By using all of these features, OPA allows you to decouple the policy logic from your software services. A side effect of this is that other people or teams can manage the policies separately from those software services.
Open Policy Agent Features
Let’s take a closer look at some of its features from a technical aspect.
OPA is designed to run, along with the software that relies on OPA’s policy decisions, on the same server. By using OPA you can effectively decouple policy decision making from the underlying software, this makes it possible to do away with hardcoded policies or having to maintain static configuration files along with the codebase.
OPA Feature: Deployment Models
Since OPA will run on the same host as the software that will “offload” the policy decision-making process, it is possible to get similar (not identical) performance compared to when you would hard couple policy decision logic into your code.
It is recommended to keep OPA as close as possible to the software that requires a decision to a policy question. A benefit of this approach is that you will not need to make an additional hop to some other host, thus decreasing your overall latency and network traffic.
OPA can be used in the following ways:
- A daemon on the host
- A tried-and-true approach, simply run a process on a host and have your applications send requests to it.
- A sidecar container
- A popular pattern where you run components of an application into a separate container, usually along with the main application itself in a different container.
- A Go library
- Should you want to wrap some additional code around OPA, this is a sound way to do just that.
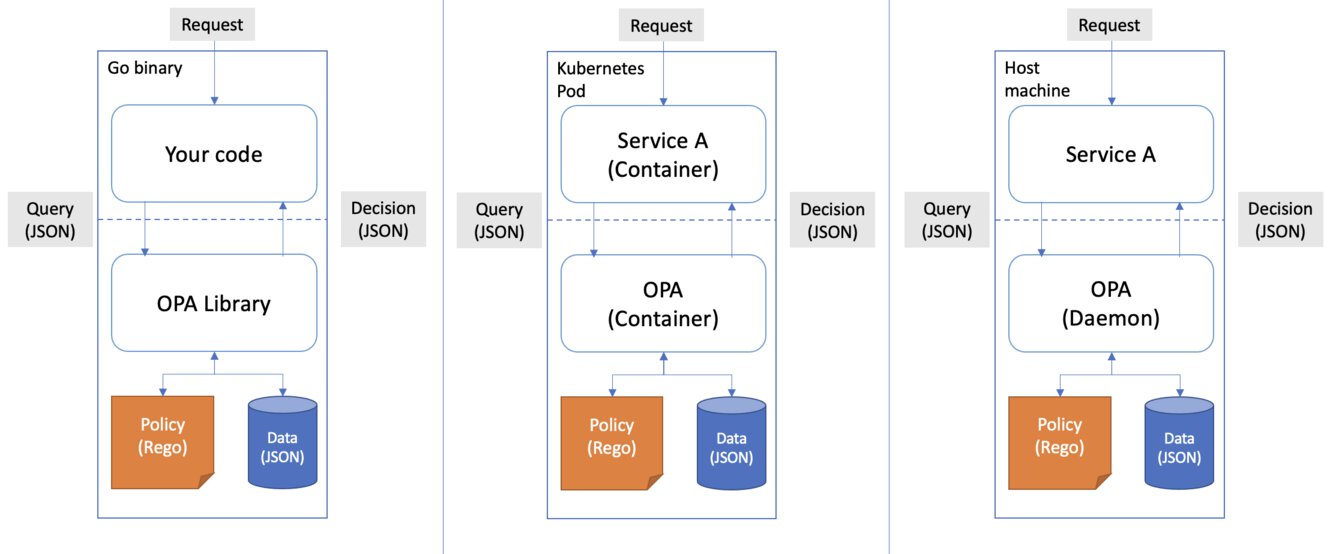
The idea is that you deploy the binary as many times as you’d like (or need), throughout your landscape. Take this example when you’re trying to integrate OPA into your containerized applications:
Let’s assume you’re running OPA as a sidecar container along with Envoy, another sidecar container. If you haven’t heard of Envoy before, it is a layer 7 proxy and communication bus designed for large modern service-oriented architectures. For simplicity’s sake let’s also assume that all traffic flowing in and out of the pod will pass through Envoy first before going to our microservice. With Envoy, it is possible to delegate authorization decisions to an external service. Using the OPA-Envoy plugin you can enforce context-aware access control policies without modifying your microservice.
The point I am getting at it is that this means that for every Kubernetes pod you’re running, you will also have a sidecar container (in other words, an instance) of OPA running. This does seem important to keep in mind, every policy and all of the data are kept in memory for every such instance, this allows OPA to be free of any runtime dependencies since it does not need to hop across the network or use an external service to get to a decision.
OPA Feature: Management APIs
Should you need to build some sort of additional control plane around OPA, you’re in luck. It exposes several domain-agnostic management APIs that your service can use to manage and enforce policies:
- Bundle API
- Distribute policies and data to OPA, via digitally signed bundles. It is one of many ways through which you can get policies and data updates cached into OPA.
- Decision Log API
- Collect logs of policy decisions made by agents.
- Health API
- Agent deployment readiness and health.
- Status API
- Collect status reports on bundle activation and agent health.
- Prometheus API
- Obtain insight into performance and errors.
OPA Feature: Tooling
OPA comes with several features to jumpstart your development experience:
- REPL (Read-Eval-Print-Loop)
- A simple interactive shell that you can use to experiment with policies. The REPL functions similarly to how any other shell works; input some command, execute some command and returns the result to you.
- Unit testing
- To quote the docs: “To help you verify the correctness of your policies, OPA also gives you a framework that you can use to write tests for your policies. By writing tests for your policies you can speed up the development process of new rules and reduce the amount of time it takes to modify rules as requirements evolve.”
- Benchmarking and profiling
- OPA comes with tools to let you profile policy evaluation, in case you need to figure out why a particular query is slow. On the other hand, there is also support for benchmarking specific policy queries which makes it easy to perform an evaluation N amount of times!
- Editor and IDE Support
- To help you kickstart your dev/test cycle, OPA can integrate with many popular editors and IDEs. The add-on pack contains features such as syntax highlighting, policy coverage, query evaluation, and others.
- Rego Playground
- Allows you to write and test policies right inside of your browser, it can even be used to publish bundles of whatever you’ve concocted, which can be pulled on your development machine! Don’t use pull bundles from the Playground to power your production environment, though.
OPA Feature: Ecosystem
Since 2020 OPA has seen a surge in its adoption on various platforms and across many layers of the stack, leading to many different types of integration projects. I can only encourage you to take a look at the full list over on the OPA docs, especially if you’re wondering whether or not your favourite product can integrate with OPA. Here are just a few of the integrations:
- Kubernetes Admission Control
- Gatekeeper
- Network Authorization
- Envoy
- Application Authorization
- OpenFaaS
- Data Filtering
- Elasticsearch
- CI/CD
- Conftest
OPA Feature: Rego
Rego (pronounced ray-go) is a general-purpose policy language, inspired by Datalog, it has been designed for writing the policies we have been talking about all this time. In Rego, policies are simply if statements that mirror the real-world policies often found in PDFs, emails and wikis. An example of such a policy could be as simple as “allow if the user is Thomas” or a little more complex such as “when Thomas is on call, only he is allowed to open customer tickets”.
The language comes with some powerful features:
- Built-ins
- When you want to write complex rules you might need to perform some simple arithmetic, etc… Rego provides this via a ton of built-in function. Out of the box it provides built-ins for the following: numbers, strings, regexs, networks (CIDR), aggregates, arrays, sets, types, encodings (base64, YAML, JSON, URL, JSON Web Tokens), time.
- Context aware policies
- OPA can be made aware of the world around it by enriching the policy decision process with “cached data”. Depending on the access pattern that is most suitable for your architecture, the data can be acquired or refreshed. OPA should then have a cache or replica of that data, just as OPA has a cache of policies. Caching the data in this manner allows for making policy decisions, for instance, based on cached data from Active Directory.
- Packages: Policies can be built in a modular and hierarchical manner by using packages, they allow you to group policies together or forces policy decision making from one module to another.
Rego syntax 101
Let’s try to wrap our head around the Rego syntax, keep the following in mind:
Rego queries are assertions on data stored in OPA. These queries can be used to define policies that enumerate instances of data that violate the expected state of the system.
When you ask OPA for a policy decision, this happens in the form of an HTTP “POST” request along with a JSON or YAML body. OPA will, in turn, respond with an HTTP response.
OPA parses your submitted request and places it under the global variable “input”, allowing you to query the data when creating your policy rules. When you want to build “context-aware policies”, policies that are aware of the state of the world around them, you will want to access the data via the “data” global variable.
You can access both of these composite objects from within your rules, be careful when you attempt to access a non-existing property because OPA will return “undefined” rather than throw an exception.
Basic Rego Rules
Rego lets you encapsulate and re-use logic with rules, which are just if-then statements. Every rule has an optional return value; if it is omitted the value defaults to true.
- For example:
- Allow is true IF user equals Thomas AND method equals GET AND the requested resource equals messages.
- Another example:
- Allow is true IF user equals Thomas AND method equals POST AND the requested resource equals messages.
Critically important: variable assignments and expressions within a rule body must succeed for the rule to succeed and for the “<value>” to be returned. For a rule to succeed, a logical AND is performed on all statements inside the rule body. The order in which the rules are written is irrelevant and you should assume that every written rule will be evaluated by OPA.
Let’s look at what this might look like in Rego, this sample is a little heavy on the comments but that’s only for illustration purposes. You can follow along with this example using the OPA Playground:
# Examples of the rule format
# ============================
# <rule-name> = <value> {...}
# <rule-name> {...}
# ============================
package api.authz.example # The name of our module
allow { # Allow is true IF
input.user == "Thomas" # input.user equals "Thomas" AND
input.method == "GET" # input.method equals "GET" AND
input.resource == "messages" # input.resource equals "resource"
}
allow = true { # Allow is true IF
postMethod := "POST" # postMethod variable is succesfully assigned string value "POST" AND
input.user == "Thomas" # input.user equals "Thomas" AND
input.method == postMethod # input.method equals to the value assigned to postMethod AND
input.resource == "messages" # input.resource equals "resource"
}
# FYI: Assignment operators (this had me confused for a while)
# ============================
# = for rule heads (single equals)
# := for inside rule bodies (colon equals)
# FYI: Equality operators (had me confused for a while, too)
# ============================
# == comparison operator (Check whether values are equal and can be used for recurssive, case-sensitive, equality checks)
# = unification operator (assigns any unassigned variables so the comparison can return true => recommended to use := and == instead)
Another critically important thing: if there are multiple rules with the same name, a logical OR will be performed after the evaluation of their respective rule bodies. Things become a little more complicated when rules with the same name do not return the same values, as complete rules must not produce multiple outputs. All of this might sound incredibly vague, but it should become more clear when we use some example input along with the rules.
Somewhat important: allow (and deny) are not keywords, they are rules (but also variables). In theory, I could have replaced allow, in the example, with something else entirely. You must settle on a variable, or a collection of variables, that conveys the correct information to you. When the policy decision response is sent back to the client it will contain the names of these variables/rules, you will see this occur in a second.
When we submit the following input against our rule:
{
"input": {
"user": "Thomas",
"method": "GET",
"resource": "messages"
}
}
The way the input is validated is something along these lines:
- Allow is true IF
- user is “Thomas” AND
- method is “GET” AND
- resource is “messages”
- OR if allow is true IF
- user is “Thomas” AND
- method is “POST” AND
- resource is “messages”
package api.authz.example
allow = true { # ✅ allow evaluates to true
input.user == "Thomas" # true AND
input.method == "GET" # true AND
input.resource == "messages" # true
}
# OR
allow = true { # ❌ allow evaluates to undefined
postMethod := "POST" # true (succeeds) AND
input.user == "Thomas" # true AND
input.method == postMethod # false AND
input.resource == "messages" # true
}
# Finally the first 'allow' evaluates to true
# The second 'allow' is undefined thus it is.. not defined.
# So the first 'allow' wins.
Our output looks like this:
{
"allow": true
}
Should we have submitted JSON input that would cause none of our input rules to succeed, the value of the allow variable would be undefined. You can try this yourself in the Rego Playground by modifying the input object. Try setting the method to “PUT” and hitting evaluate, since we have no logic for how to handle “PUT” would cause the allow property to be omitted from the response and thus returning an empty JSON object in our response.
{}
If you want to avoid that, the best thing to do is to assign a different default value. The default value is used when all of the rules sharing the same name are undefined.
default allow = false # single equal sign
One last tangent I want to make; it is possible to write if-then-else statements using the "ELSE" keyword, to have prioritized rule evaluation.
🤔 If you’re thinking of writing if-then-else statements for performance reasons, you do not need to do this. OPA attempts to perform indexation on the rules that you’ve written for them to execute quickly. From what I was able to gather, I think it is still the case that the use of “
ELSE” disables these optimizations. I couldn’t find a clear answer in the docs or in OPA’s pull-requests. I did find that OPA’s devs recommend that we make rule bodies mutually exclusive instead.
Interation in Rego
You can follow along with the next example via the OPA playground.
Time to go one step further, expanding upon the previous example. Let’s assume that we push data into OPA, which holds information about a role-based access control system. We can use that data to check whether or not our user is allowed to perform a specific method. Ideally, you will want to use groups for this sort of stuff, as keeping track of usernames does not seem like a great idea to do in a production setting. Again, the data JSON you will see here is just for illustration purposes.
{
"assignments": [
{
"role": "messages/reader",
"user": "Thomas"
},
{
"role": "messages/reader",
"user": "Foo"
},
{
"role": "messages/writer",
"user": "Foo"
}
],
"roles": [
{
"action": "GET",
"name": "messages/reader",
"resource": "messages"
},
{
"action": "POST",
"name": "messages/writer",
"resource": "messages"
}
]
}
We can use iteration to see if the user exists in the list of assignments, should the user have one or more role assignments then we can check whether or not the requested action is allowed on that specific resource.
It will help to take a look at this from a traditional programming language perspective.
for ($i = 0; $i -lt $assignments.Count; $i++) {
if ($assignments[$i].User -eq $input.User) {
return $true
}
}
return $false
In Rego, you need to think a little differently. Here we will be saying that there must be some array element, that has a user property whose value is equal to “input.user”.
some i # Some array element i
data.assignments[i].user == input.user # Contains a property "user" that should equal to input.user
# note that the indentation is purely visual
# it has no impact on the iteration
We will also refactor our policy from earlier so that it uses a partial set rule. Partial set rules are quite similar to regular rules since they are simply if-then statements! These rules generate a set of values, after which the set is assigned to a variable.
To quote the OPA docs:
Set documents are collections of values without keys. OPA represents set documents as arrays when serializing to JSON or other formats that do not support a set data type. The important distinction between sets and arrays or objects is that sets are unkeyed while arrays and objects are keyed, i.e., you cannot refer to the index of an element within a set.
🤔 Keep in mind that when you work with a set, in Rego, it will be handled as an unordered collection of unique values and not as an array. To see this in action, head on over to the OPA playground, click the evaluate button and see the differences in output.
Back to our example, let’s refactor the rule to the following statements:
package api.authz.example
default allow = false # Make it so our allow rule always returns value false
# instead of it being omitted from the response when undefined
allow {
some role_assignment
user_has_role_assignments[role_assignment] # For each role_assignment in role_assignments
some i
role := data.roles[i] # For each role in roles
role.action == input.method # If role.action equals to input.action AND
role.resource == input.resource # If role.resource equals to input.resource AND
role.name == role_assignment # If role.name equals to role_assignment
}
user_has_role_assignments[role_assignment] { # A role_assignment is added to the set if..
some i
assignment := data.assignments[i] # For each assignment in data.assignments
assignment.user == input.user # If assignment.user equals input.user
role_assignment := assignment.role # Add assignment.role to the set
}
When we submit a slightly different input compared to earlier, against our refactored rule:
{
"input": {
"user": "Foo",
"method": "GET",
"resource": "messages"
}
}
The partial rule “user_has_role_assignments” will generate is a set with two unique entries, since user “Foo” has two assignments. The resulting set should translate to the following JSON array:
["messages/reader", "messages/writer"]
The complete rule “allow” should generate “true” for this input.
{
"allow": true,
"user_has_role_assignments": [
"messages/reader",
"messages/writer"
]
}
Changing the value of the input object’s user to “Bar” should cause the rule to evaluate to “false”.
{
"allow": false,
"user_has_role_assignments": []
}
Closing thoughts
In my opinion, OPA comes packed with a ton of solid features: from the developer experience, management APIs and extensibility, to its lightning-fast performance and small footprint. Maybe it can be of use to you the next time you are required to integrate, or even design and build, a policy decision mechanism.
Perhaps it was just me, but I did find that the learning curve for Rego was a little steep, initially. In the beginning I felt as if I was fumbling around quite a bit. 😅
Fortunately, this was only temporary! After some searching, I ended up taking Styra Academy’s excellent “OPA Policy Authoring” course, which cleared up so many of the remaining misconceptions that I had about the language. I think this was due to me thinking too much in terms of C-like paradigms, however after making things click I was able to do understand and appreciate the Rego paradigm.
If you believe I might have missed something or should I have written something that is entirely incorrect, please feel free to let me know!
Related posts
- Azure Purview
- Azure Resource Locks
- Local OpenShift 4 with Azure App Services on Azure Arc
- Azure Red Hat OpenShift 4
- Microsoft Entra Privileged Identity Management (for Azure Resources) Revisited
- Azure Policies & Azure AD PIM breakdown - Part 2
- Azure Policies & Azure AD PIM breakdown - Part 1
- Azure Chaos Studio and PowerShell
- Azure Chaos Studio - Public Preview
- Verifying Azure AD tenant availability
- Azure Linux OS Guard on Azure Kubernetes Service
- Exploring AI CPU-Inferencing with Azure Cobalt 100
- Windows Containers: Azure Pipeline Agents with Entra Workload ID in Azure Kubernetes Service
- Register Azure Pipeline Agents using Entra Workload ID on Azure Kubernetes Service
- SPIFFE and Entra Workload Identity Federation