Kubernetes in a Microsoft World - Part 2
In this post
In May 2019 my colleague Micha Wets and I met for Azure Saturday 2019 at the Microsoft HQ in Munich to talk about Kubernetes in a Microsoft World. We discussed what such a world would look like for someone who is primarily running a Microsoft-based technology stack. And in more detail, we showed the audience what we’ve noticed amongst our own customers, innovations in Windows Server Containers and how Kubernetes works with Windows-based worker nodes.
Even though some time has passed and this post might seem rather irrelevant at first glance, I frequently come across system- and software engineers that have not yet had the pleasure of getting their hands dirty with this technology. More of often than not they have heard of the benefits that containers can bring to the table; which most of the people I’ve spoken to will link to performance (though this not always the case). Hopefully this blog post can solidify your own understanding of containers, Kubernetes and how it all fits.

Kubernetes
I think it’s safe to say that, regardless of whether you are a developer or ops person, containers can be extremely valuable tools. We can now move past most of the wiki pages, Sharepoint pages, emails and PDF documents that detail how to install and update our applications.
But now your business department is telling you that they are want to roll out updates faster, preferably multiple times per week or at the end of every sprint. You also need to be able to scale out, avoid network issues and manage your application on multiple hosts. But what if there’s an issue with one of the hosts or your application stops responding? How are we going to manage all of those potential issues? -We’re not going to RDP or SSH into every box and execute docker commands, that’s a fool’s game.
There has to be a system that can do most of the heavy lifting for us or something that can give us the foundation for building the tools that we need to keep our infrastructure running. That is where Kubernetes comes in.
Kubernetes brings three big advantages to the table. There are features that we’ve come to expect of managed cloud offerings so it is nice to see K8s supports them right out of the box.
- Portability
- You can, to a certain extent, use the same configuration files and tools to manage your clusters running on-premise, at a cloud provider or in a hybrid model that spans multiple datacenters.
- Extensibility
- You have the option of writing your own controller logic and tapping into other Kubernetes addon projects.
- Self-healing
- Kubernetes can made use that containers are places on nodes that have sufficient resources available to them. Some of these features : automatic pod restarts based off of custom health probe logic, auto-replication and auto-scaling
K8s Architecture 101
You will be doing most of your administrative tasks through the kubectl CLI tool, which is highlighted at the top.
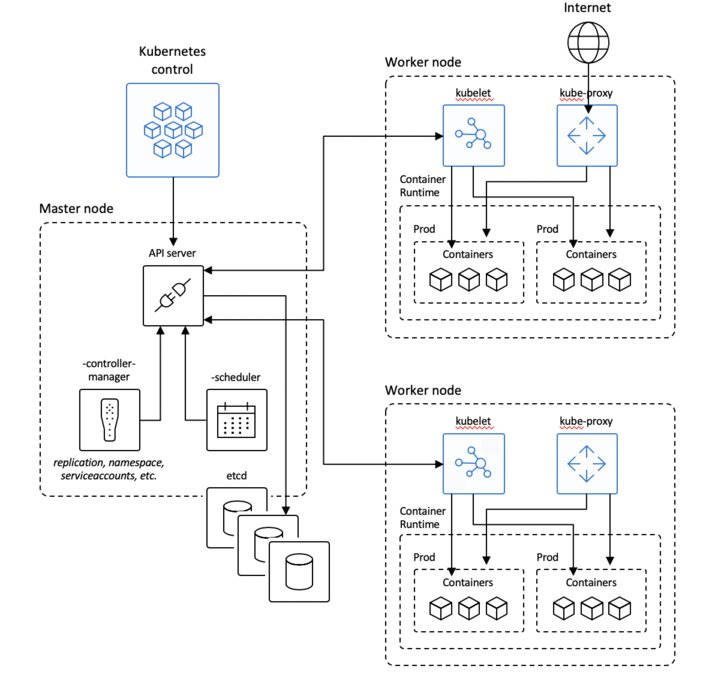
Master node
Kubernetes has one, preferably more, master nodes. A master node handles all cluster operations, monitoring and scheduling, and is the primary access point for cluster administration.
The master nodes consist out of a few blocks. The API service which is the primary endpoint for doing all sorts of administrative tasks, it is a stateless web app so you need something to store your cluster state. The cluster store, usually etcd, fulfills this role; it persists the state of your configured kubernetes objects.
On to the scheduler.. Like schedulers that come with operating systems its job is to determine where a specific workload needs to run. So based on a pods resource requirements it will determine the best node for the pod to run on.
Controller Manager’s main function is to keep things in the desired state. It does this by running controllers that watch the current state of the system and update the api server to ensure that we’re always heading towards a desired state.
Worker node
Next up is the node, which is where our applications, inside of pods, run. A worker node’s main job is to start and ensure that pods run. It also implements networking rules and ensure network reachability to the pods and the services. Clusters typically consist out of multiple nodes and this is something that you want to figure out in advance. Ask yourself “what are my scalability requirements for this particular setup?”
The Kubelet is the primary “node agent” that runs on each node. It monitors API server for changes by asking the API server whether or not it has new workloads, the Kubelet will receive PodSpecs in the form of a YAML or JSON file. It then becomes responsible for the lifecycle of those pods, so starting and stopping pods in reaction to state changes. The Kubelet will also report the node and pod state back to the API server because the scheduler needs to know whether or not a node is ready to receive workloads or know if an application inside a pod is still healthy. More on what a Pod is in a second but for now just know that it is a construct for defining one or more containers. Think along the lines of a VM running one or more applications.
Kube-proxy is responsible for all networking components for nodes. It does this behind the scenes with the network proxy that is implemented in iptables. This piece of software is generally also responsible for creating things like services and routing/load balancing traffic to the correct pods.
A container runtime is the software that is responsible for running containers. Kubernetes supports several container runtimes: Docker, containerd, cri-o, rktlet and any implementation of the Kubernetes CRI (Container Runtime Interface). The runtime will ensure that container images are downloaded and can be started.
Azure Kubernetes Service
So at a first glance it might seem daunting to set up and manage all of this infrastructure, especially if you are just starting out. There are also many different flavours of Kubernetes and to “make matters worse” you will find about a dozen different best practices online. The question at the end of that road still remains: “how do I get started?”. If you are like me and you work with Microsoft Azure for the majority of your time you might want to take a look at Azure Kubernetes Service or AKS as it is often referred to.
AKS takes away a lot of the potential headaches that you might encounter when setting up your own cluster on Azure. Microsoft is kind enough to manage the entire control plane (master nodes) for you, according by their own best practices. By doing this Microsoft ensures that your AKS control plane is set up in a high-available manner, at no additional costs.
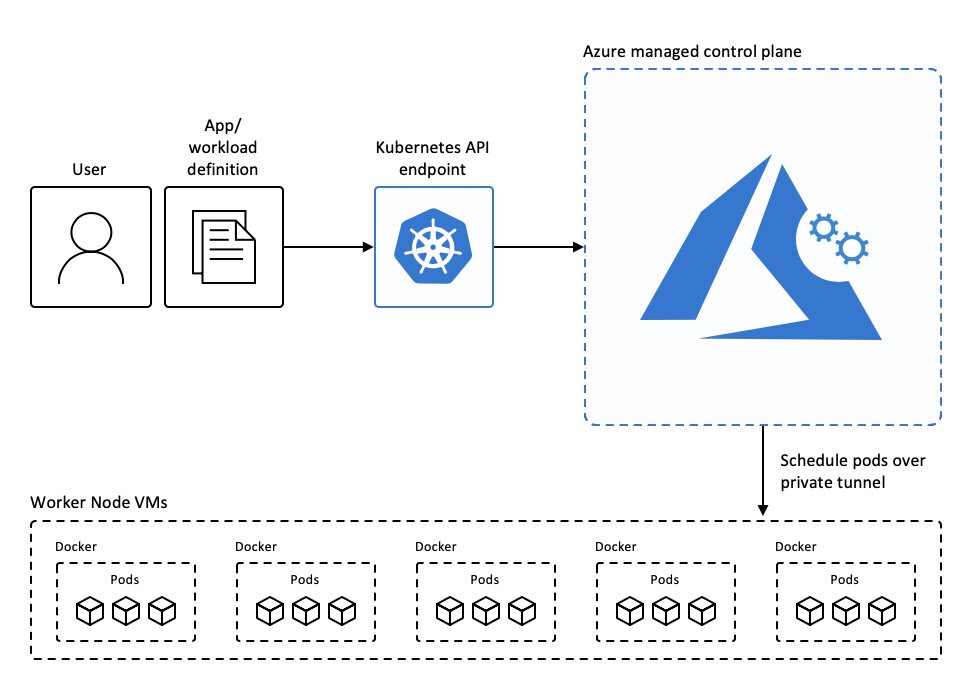
On the worker nodes side of things, Microsoft will push out security patches to your Linux nodes for you and you will only need to schedule a reboot of your node in order to apply the patches. (I should point out that Windows nodes support is still in preview, Windows Update does not periodically run on these nodes. You must “upgrade” your node pool through the az aks nodepool upgrade command in the Azure CLI. According to Microsoft the upgrade process creates nodes that run the latest Windows Server image and patches, then removes the older nodes.)
You can easily and automagically scale nodes up or down if you wish. This is useful since you are billed in the same manner that you are normally billed for using Azure compute and storage services, by what you consume. Since AKS spins up additional worker nodes in the form of Azure Virtual Machines you can potentially combine this with Azure Reserved instances, which allows you to reserve a certain amount of CPU cores for a specific Azure VM series for a certain amount of time (one or three years). Whenever you place such a reservation you can get some significant discounts compared to just paying for your VM every month.
Kubernetes Building Blocks
Whenever people ask me what to do next after setting up an AKS cluster I usually tell them to get familiar with a couple of basic building blocks. These are the things I think you should know if you want to get an application up and running on Kubernetes.
Pods
I’ve already mentioned this briefly but let’s dig in to it a little more.
A pod is the simplest unit in the Kubernetes object model that you create or deploy, it is a wrapper around one or more containers. If you’re used to working with virtual machines then you could compare a pod to a virtual machine. It is an environment where containers live until the pod is gone. The containers inside the pod will all share a single, unique pod IP. The containers will share the pod’s storage, resources and also lifecycle meaning that when a pod dies, all containers within that pod dies as well and the resources are reclaimed.
Deployments and ReplicaSets
These two concepts are essential parts to achieving and (perhaps more importantly) maintaining a desired state in the cluster.
A ReplicaSet is a type of controller that is, for a lack of a better explanation, like a cluster wide process manager. It will make sure that certain pod is running with a specific amount of replicas on the cluster at all times. It’s the scheduler’s job to make sure that these pods are placed on a node that has sufficient resources (memory, cpu, etc..). For instance; I could tell Kubernetes that I would like to have three instances of NGINX running at all times. If a pod running NGINX goes does the controller is going to try to ensure that a new pod gets created so that we end up with three operational instances.
A deployment is a concept that builds on top of ReplicaSets and allows you to move back and forth between versions of your application. It allows you to achieve your desired state, in a controlled way, by using a rolling update strategy.
Services
Service discovery becomes critical in a system like Kubernetes. Assume that we are dynamically provisioning new pods we might encounter a new problem.. Let’s assume that some set of back-end pods provide functionality to front-end pods. How do the front-end pods find out and keep track of which back-end pods are in a ReplicaSet? Do we maintain a list of potential IPs or hostnames inside of our front-end pods so they know where to send their requests to?
Let’s not go down that road.
A service is a networking abstraction that defines a logical set of pods and a policy by which to access them, which is usually though adding labels to the pods. Think of labels as arbitrary key/value pairs, our back-end pods can sit behind a back-end service that will basically load balance the request to one of our back-end pods!
These services have a stable IP and can have a DNS name if you use the CoreDNS (installed by default as of K8s 1.11+) or Kube-dns (optional) addons.
Storage
Can you run stateful services, databases and the like, on Kubernetes? Yes you can.
You have to keep in mind that if a pod dies the underlying storage is also reclaimed, persistent volumes essentially solve this problem. With persistent volumes we can make sure that a pod is always hooked up to a specific volume by using a volume claim.
A Persistent Volume is a base abstraction for a piece of storage and its actual implementation is up to cloud providers. In the case of Microsoft Azure it is backed by an Azure Managed Disk or Azure File Share. In other words a Persistent Volume carries the details of a piece of real world storage that has been made available to cluster users, ready to be consumed, through the Kubernetes API.
There are a two ways that you can work with Persistent Volumes:
Static Storage Provisioning
An administrator pre-provisions several disks and essentially builds up a pool. A developer can then use a Persistent Volume Claim for a specific volume and reference it in the pod specification.
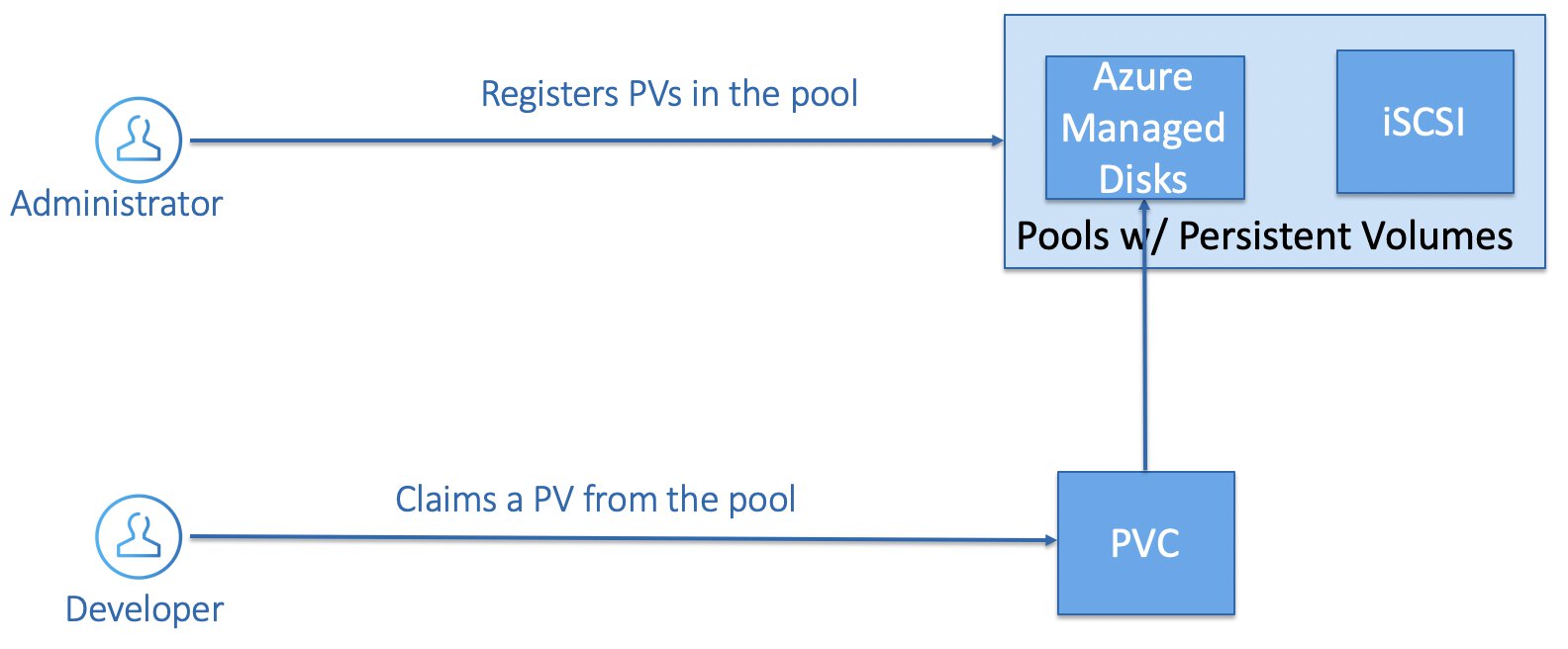
A Persistent Volume Claim has a unique name that you declare in your PodSpec, that way you will always end up with the same Persistent Volume.
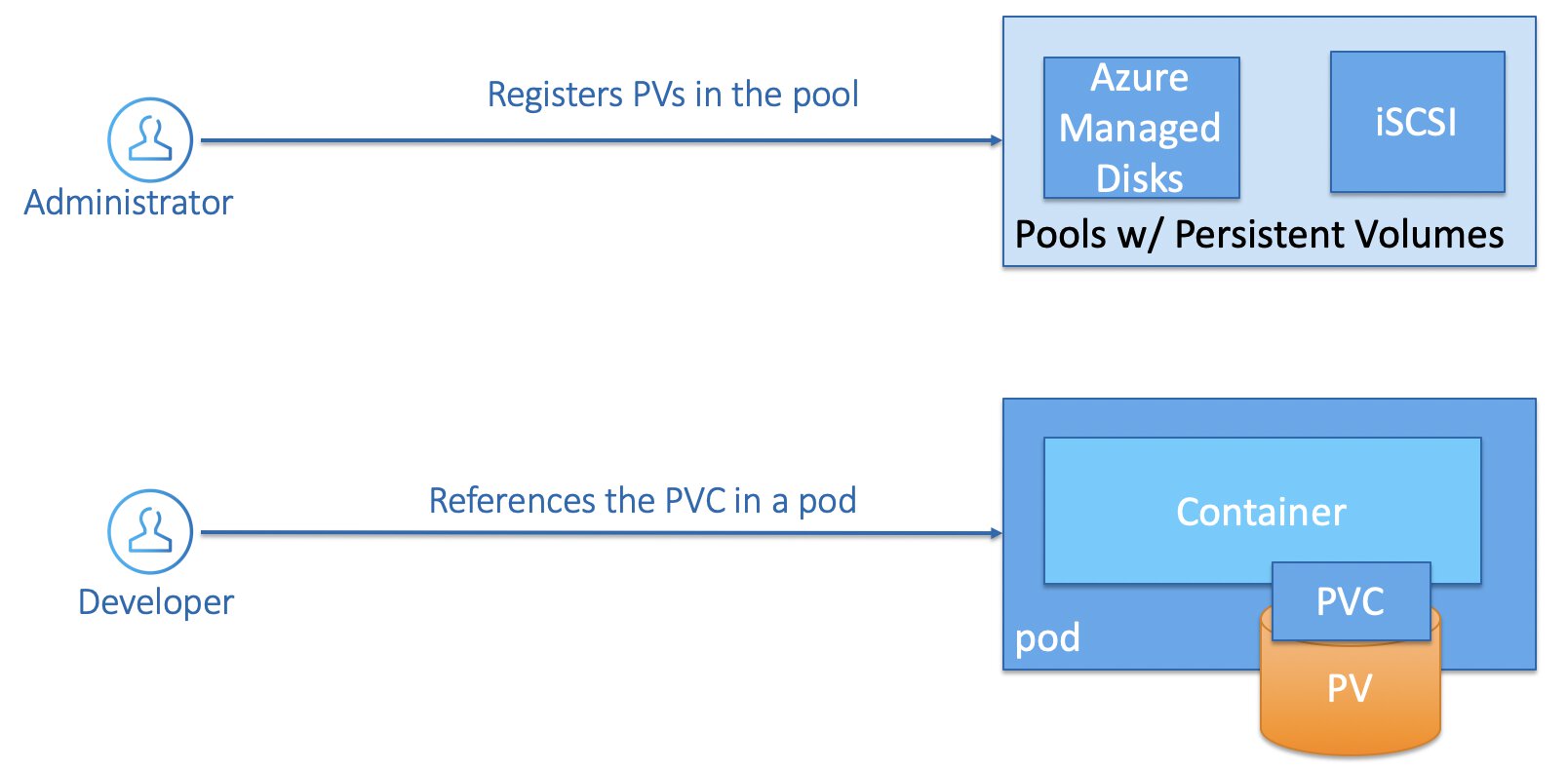
Dynamic Storage Provisioning
Another way to provision storage on Kubernetes is by having an administrator registers several storage classes, you can think of storage classes as different storage profiles that you want to provider to the cluster user in advance. They will be able to create new persistent volumes themselves but only persistent volumes that are configured according to what you have defined in advance.
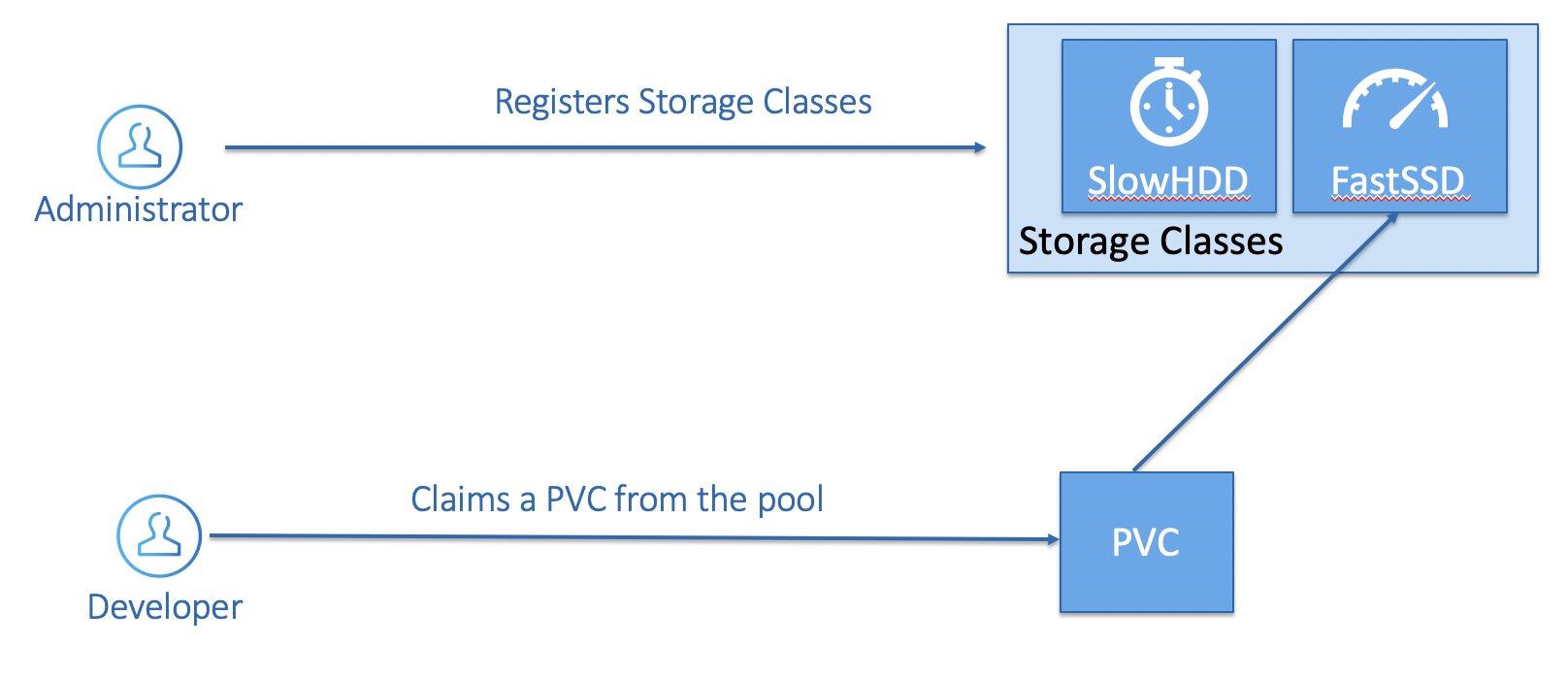
Take this simple example of two fictional storage classes that we have defined on our fictional cluster:
- SlowHDD, which is mapped to a standard tier HDD Azure Managed Disk.
- FastSSD, which is mapped to a premium tier SSD Azure Managed Disk.
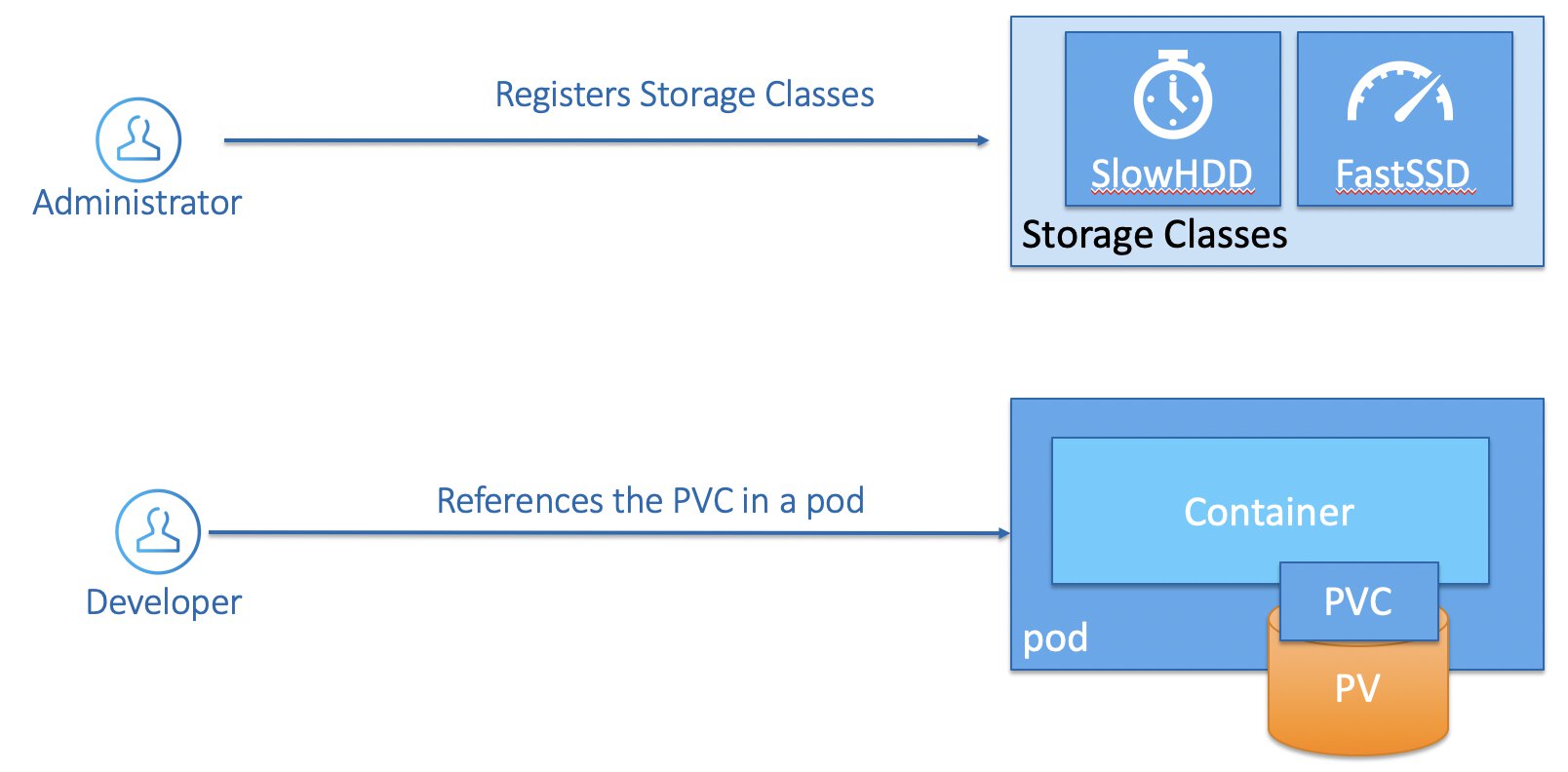
A cluster user creates a Persistent Volume Claim, that this time references Persistent Volume that was provisioned through a the storage class. And then it is business as usual, you place the Persistent Volume Claim inside of your PodSpec.
A final note on Stateful workloads
Before anyone tries to come out me for suggesting that you should run a stateful workloads solely on pods or through a deployment think again. You probably want to take a look at StatefulSets before doing so.
I do believe that there are use cases for dev/test/acceptance environments to have so called “disposable stateful workloads”. It might be incredibly useful to have a new SQL Server deployment with every new deployment so you are able to test run your migration scripts.
Namespaces
Now this isn’t something we discussed but while I was writing this post I thought it might be worth to mention this.
Namespaces are a way to logically divide most cluster resources from each other. So called “low level” resources, such as nodes and Persistent Volumes are not in any namespace. Names of resources need to be unique within a namespace, but not across namespaces. Namespaces can not be nested inside one another and each Kubernetes resource can only be in one namespace.
Let’s say you have a service in a specific namespace, this will create a corresponding DNS entry. his entry is of the form <service-name>.<namespace-name>.svc.cluster.local, which means that if container just uses <service-name>, it will resolve to the service which is local to a namespace. This is useful for using the same configuration across multiple namespaces such as development, Staging and Production. If you want to reach across namespaces, you need to use the fully qualified domain name (FQDN).
If you do not want resources to be accessed across namespaces, you can absolutely lock this kind of behavior down using Network Policies so long as your network plugin interface (CNI) supports network Policies.
- Tags |
- Azure
- Kubernetes
Related posts
- Kubernetes in a Microsoft World - Part 3
- Kubernetes in a Microsoft World - Part 1
- Azure Linux OS Guard on Azure Kubernetes Service
- Windows Containers: Azure Pipeline Agents with Entra Workload ID in Azure Kubernetes Service
- Register Azure Pipeline Agents using Entra Workload ID on Azure Kubernetes Service
- Azure Confidential Computing: CoCo - Confidential Containers
- Local OpenShift 4 with Azure App Services on Azure Arc
- Open Policy Agent
- Azure Red Hat OpenShift 4